
Wie bindet man DataStage an? | Umzug eines DWH auf eine Snowflake - Teil 3
In den ersten beiden Teilen dieser Blog-Reihe haben wir uns den Kontext angeschaut, in dem wir uns mit dem Umzug von Oracle zur Snowflake beschäftigen. In diesem Teil geht es jetzt um die Anbindung von DataStage an Snowflake.
DataStage Version
Mit DataStage V11.5 wurde die Snowflake ConnectorStage eingeführt, die auf den JDBC-Treiber von Snowflake aufsetzt und die Erweiterungen von Snowflake unterstützt.
Jetzt aber ein paar „Abers“ zu dieser Version:
- Diese ConnectorStage gibt es generell nur für Parallel Jobs und nicht für Server Jobs.
- Die Unterstützung einer Snowflake ist nur rudimentär in V11.5 implementiert. Sehr wichtige Funktionen (s.a. das nächste Kapitel und Teil 6 zum LOAD und MERGE) sind erst in späteren DataStage Releases hinzugekommen.

Um es deutlich zu sagen: Mit einer V11.5. (oder niedriger) solltest du gar nicht erst starten. Es ist mindestens die V11.7.1.1 notwendig! Aktualisiere auf den neuesten JDBC-Treiber, da die von IBM mitgelieferte Version V3.5 des JDBC Treibers von Snowflake nicht mehr unterstützt wird!
Fazit
Plane eine Phase vor deinem Projekt ein, um DataStage auf die richtige Version zu bringen und die notwendigen Treiber für Snowflake zu aktualisieren und zu testen.
JDBC, ODBC, Server Jobs und Parallel Jobs
Die folgenden Möglichkeiten gibt es, um einen DataStage Job an eine Snowflake anzubinden:

Erklärung
- Ja – das geht
- Nein – das geht nicht
- Jein – das kannst du so machen, aber dann ist es $§&?/&/§%/(& – nicht gut. Im Hinblick auf Performance willst du das nicht machen, niemals!
ODBC Connector Stage
Für Parallel und Server Jobs gibt es theoretisch die Möglichkeit, die ODBC-Stage zu nutzen. Da DataStage unter Linux die ODBC-Treiber von DataDirect benutzt, müsste entweder dieser Treiber genutzt werden oder DataStage wird komplett auf einen anderen Treiber-Manager konfiguriert. Das betrifft dann aber alle ODBC-Datenquellen!
Dieses Verfahren ist von IBM dokumentiert:
Link: https://www.ibm.com/docs/en/iis/11.7?topic=ahul-configuring-other-odbc-drivers
Technisch kannst du den einen oder den andern Weg gehen, aber das sind beides keine sinnvollen Wege. DataStage nutzt „nur“ den ODBC-Standard. Bei Änderung von Daten werden die normalen UPDATE/DELETE Befehle ausgeführt. Und die haben bei einer Snowflake eine sehr schlechte, eigentlich eine nicht vorhandene Performance (darüber hatten wir schon in Teil 2 gesprochen). Noch mal zur Wiederholung: Wir reden hier von maximal 1 Zeile pro Sekunde bei UPDATE und DELETE Befehlen!
Mal eben 30.000 Sätze per DataStage Job zu verändern, dauert schon mal 8h. Und die Parallelität in DataStage zu erhöhen, bringt nichts, da die Tabelle bei einem UPDATE-Befehl gesperrt wird.
JDBC ConnectorStage
Die JDBC ConnectorStage ist eine generische Stage, um beliebige Datenbanken, für die ein JDBC-Treiber existiert, anzubinden. Grundsätzlich funktioniert sie auch mit Snowflake, aber alles, was zur UPDATE/DELETE-Performance bei ODBC gesagt wurde, gilt auch hier.
Snowflake ConnectorStage
Erst mit den individuellen Erweiterungen, die von Snowflake im JDBC-Treiber eingebaut sind und die von DataStage erst in der V11.7.1.1 richtig unterstützt werden, ist es möglich einen DataStage Job performant mit einer Snowflake arbeiten zu lassen. Mehr dazu im nächsten Kapitel und in Teil 5.
Fazit
- Server Jobs können nicht sinnvoll migriert werden. Arbeitet eins deiner DataStage Projekte hauptsächlich mit Server Jobs, dann musst du den Refactoring-Weg gehen
- Die Standard-Datenbank Connectoren für ODBC und JDBC können nicht sinnvoll genutzt werden.
- Die Snowflake ConnectorStage ist die einzige sinnvolle Datenbank-Stage bei Snowflake!
Snowflake und die Snowflake ConnectorStage
Im Teil 2 hatten wir einige Besonderheiten der Snowflake aufgeführt, die sich auch auf die ETL-Verarbeitung auswirken. Wir wollen uns das hier jetzt genauer anschauen.
Die Snowflake ConnectorStage erlaubt keine Reject-Links!
Eine Verarbeitung, die auf Reject-Links aufbaut, muss entfernt werden.
Manuell ist das ein mühsamer Prozess.
Mit dem JobManipulator kannst du Reject-Links und alle direkt davon abhängigen Stages (automatisiert) entfernen!
Schreibmodus “Load from file”
DataStage bietet analog zu Db2 oder Oracle ConnectorStages auch bei der Snowflake einen Schreibmodus „Load from file“ an, der nicht mit einem „normalen“ SQL INSERT arbeitet, sondern ein Lade-Verfahren passend zur Datenbank nutzt. In der Regel wird damit eine viel bessere Performance als mit einem INSERT erzielt.
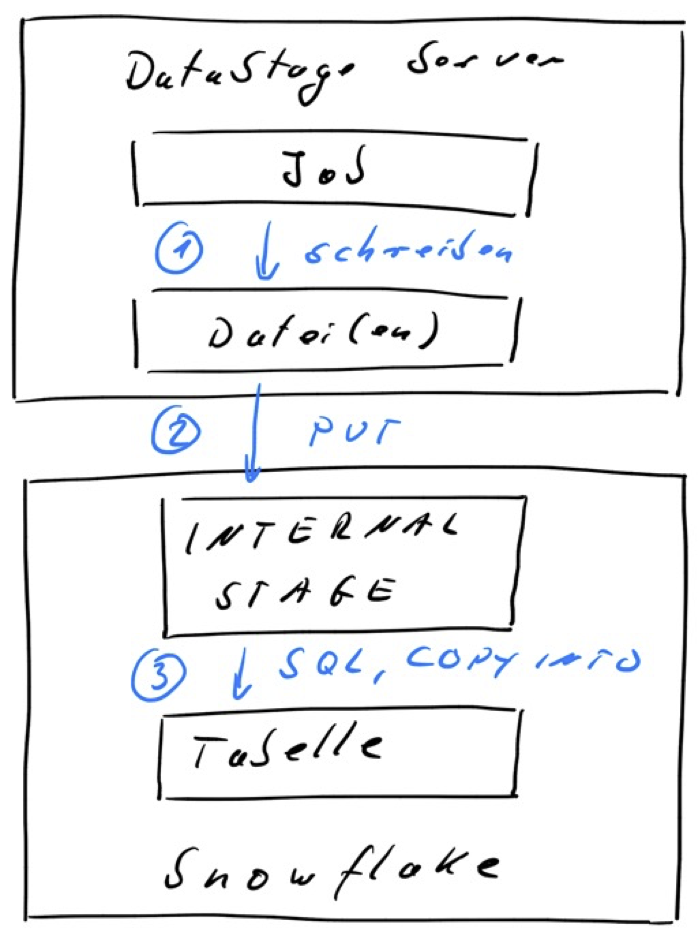
Bei Snowflake wird dazu der PUT und COPY Befehl und eine Snowflake INTERNAL STAGE genutzt und mit temporären Dateien auf dem DataStage Server gearbeitet.
Ablauf:
- Die ConnectorStage schreibt die Daten vom Eingabelink in eine temporäre Datei.
- Diese Datei wird mittels des Snowflake PUT-Befehl in eine INTERNAL STAGE geschrieben.
- Im letzten Schritt werden die Daten mittels COPY INTO in die Zieltabelle geschrieben.
Hier die Snowflake Dokumentation dazu:
- PUT: https://docs.snowflake.com/en/sql-reference/sql/put.html
- COPY INTO: https://docs.snowflake.com/en/sql-reference/sql/copy-into-table.html
- INTERNAL STAGE: https://docs.snowflake.com/en/sql-reference/sql/create-stage.html
Im Teil 6 werden wir genauer auf die Parametrisierung dazu eingehen.
SQL-Dialekt
In einem DataStage Job kann ein Entwickler manuelles SQL vorgeben oder das SQL von DataStage generieren lassen. Typisch ist, dass schreibende Stages das SQL generieren. In lesenden Stages ist es sehr beliebt komplexe SELECT Anweisungen zu schreiben, um das Design des DataStage Jobs einfacher zu halten. Das ist grundsätzlich nicht verwerflich, führt aber dazu, dass bei einer Migration von ETL-Abläufen der Entwickler sich diese SQLs sehr genau ansehen muss.
Je mehr manuelle SQL-Statements in den ConnectorStages genutzt werden, desto schwieriger wird eine Job-Migration, da sich das SQL zwischen einer Oracle und Snowflake doch unterscheiden kann. Mehr dazu in Teil 5, wo wir für einige SQL-Elemente einen Vergleich zwischen Oracle und Snowflake machen.
Verwaltungs-SQL
In einem Datenintegrationsprozess gibt es nicht nur „die“ Daten-verarbeitenden ETL-Jobs, sondern viele funktionale Komponenten, die ebenfalls umgestellt werden müssen:
- Häufig werden einige Funktionen per Datenbank-Skript aus DataStage Sequenzen oder aus Shell-Skripts heraus aufgerufen. Bei einer Snowflake gibt es zwar SnowSQL, aber es ist in der Funktionalität und im Fehlerhandling nicht mit Oracle SQL*Plus zu vergleichen.
- Sehr häufig werden in ETL-Jobs Partitionen bearbeitet oder nach einer Verarbeitung Statistiken gesammelt. Beispiel: Daten werden gelesen, transformiert und in eine Tabelle geschrieben, die per PARTITION EXCHANGE dann in eine größere Tabelle gehängt wird. Auf dem Weg werden Indizes neu erstellt und Statistiken gesammelt. Bei einer Snowflake fällt das alles ersatzlos weg!
- Es gibt Projekte, die Materialized Views im ETL-Prozess verwenden. Diese können mit Snowflake so nicht genutzt werden.
Häufig werden bei DataStage diese Funktionen in den sogenannten before/after SQL-Anweisungen ausgeführt. Im Rahmen der Migration von ETL-Abläufen müssen auch diese Anweisungen angepasst werden.
Fazit
- Eine Job-Migration ist mehr als nur die ConnectorStage in einem ETL-Job auszutauschen.
- Für einige Besonderheiten der Snowflake DB sowie der Snowflake ConnectorStage sind im JobManipulator Funktionen eingebaut, um den Umstellungsprozess automatisiert durchführen zu können (da gehen wir in den nächsten Teilen genauer drauf ein).
- Insbesondere durch die unterschiedlichen SQL-Dialekte und wenn viel manuelles SQL implementiert wurde (insbesondere in Teil 5 schauen wir uns einige Unterschiede vom SQL von Oracle und Snowflake an), können auch nach der Umstellung mit dem JobManipulator noch Anpassungen per manuellem Eingriff erforderlich sein.
Hier findest du die anderen Teile dieser Blogserie
1 - Umzug eines DWH auf eine Snowflake
3 - Wie bindet man DataStage an?
4 - Wie erfolgt die Migration von DataStage ETL-Jobs
5 - Lasst uns in die Snowflake abtauchen
6 - Wichtige Details bei der Anbindung von DataStage an Snowflake