Wie erfolgt die Migration von DataStage ETL-Jobs? | Umzug eines DWH auf eine Snowflake - Teil 4
In Teil 3 haben wir uns angesehen, wie DataStage an eine Snowflake angebunden werden kann. In diesem Teil wollen wir uns ansehen, wie ein Job umgestellt wird und wie der ITGAIN JobManipulator das vereinfacht.
Organisation der DataStage Projekte
Der eigentliche Umzug der Daten und der ETL-Prozesse von Oracle auf die Snowflake wird einige Zeit benötigen.
Je nach Datenvolumen kann das reine Kopieren der Daten schon mehrere Tage (oder Wochen) dauern. Snowflake bietet verschiedene Möglichkeiten, um das zu beschleunigen. Darauf gehen wir hier nicht weiter ein.
Deshalb ist es entscheidend, dass ein Umzug wie eine große Weiterentwicklung behandelt werden muss. Du benötigst in der Entwicklung bis zu drei DataStage Projekte:
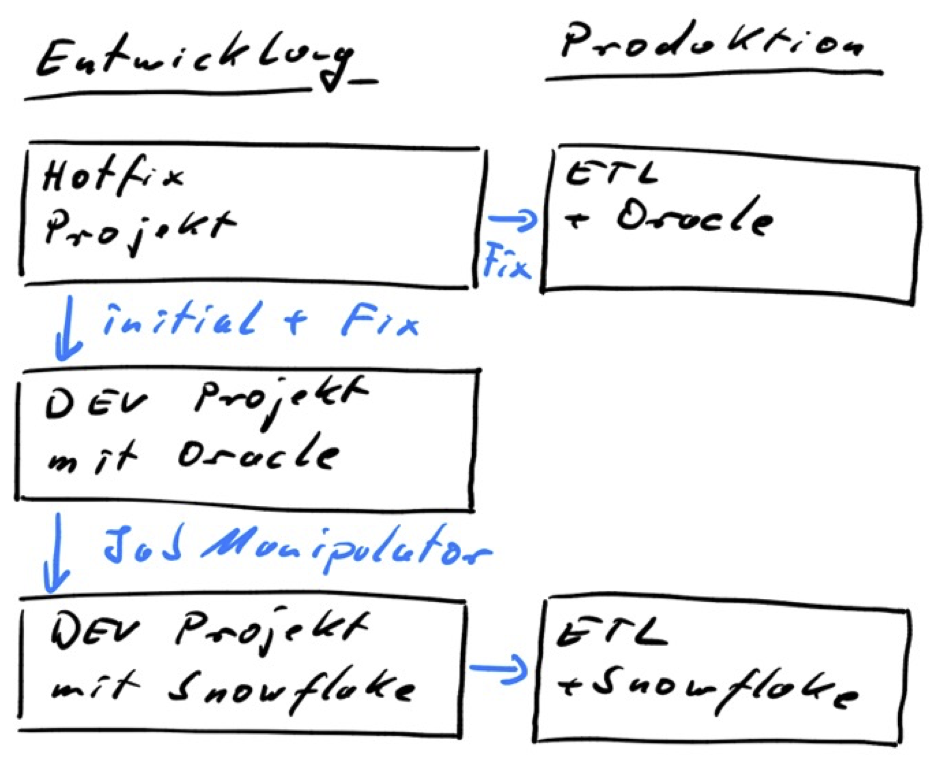
- Für die Alt-Abläufe sollte die Weiterentwicklung möglichst eingefroren werden. Allerdings solltest du dir ein DataStage Projekt als Hotfix-Umgebung reservieren.
- Dann benötigst du eine davon losgelöste Zielumgebung mit der Snowflake und einem eigenen DataStage Projekt, das die auf die Snowflake migrierten ETL-Abläufe enthält.
- Nach unserer Erfahrung benötigst du noch ein drittes DataStage Projekt, das eine Kopie der Originaljobs enthält.
Hinweis: Auf Test- oder Abnahme-Umgebungen haben wir in diesem Bild verzichtet. Die gibt es wie gehabt als Zwischenschritt von der Entwicklung in die Produktion.
Das dritte DataStage Projekt wird immer dann benötigt, wenn du Änderungen an den Ursprungsabläufen machen musst, die nicht über die Hotfix-Umgebung in die bestehende Produktionsumgebung übertragen werden sollen oder(!) können.
Das können sein:
- Anpassungen am manuellen SQL, weil sich da inkompatible Änderung ergeben haben (s. Teil 5 unserer Blog-Reihe).
- Wir hatten auch den Fall, dass das eingesetzte ETL-Framework des Kunden für Snowflake angepasst werden musste.
Die Hotfix Umgebung wird sich nicht vermeiden lassen, da sich Änderungen in den Alt-Abläufen leider nie ganz verhindern lassen. Aber, reduziere diese Änderungen möglichst auf ein Minimum! So gut wie jede Änderung in der Hotfix-Umgebung wirst du ja auch in die migrierten Abläufe übernehmen müssen. Da ist es dann wirklich vorteilhaft, wenn die Migration der ETL-Abläufe automatisiert durchgeführt werden kann.
Fazit
- Die Migration wird länger dauern, d.h. auf jeden Fall mehrere Wochen und bei großem DWH Anwendungen mehrere Monate.
- Stelle verschiedene Umgebungen für die Migration der ETL-Abläufe bereit.
Umstellung der Datenbank ConnectorStage
DataStage Jobs nutzen ConnectorStages, um Datenbanken anzubinden. Bis auf die generischen ODBC- oder JDBC-Stages hat jede Datenbank ihre eigene ConnectorStage.
Die Migration eines DataStage Jobs von Oracle zu Snowflake bedeutet, dass der Job geändert werden muss, in dem die alte ConnectorStage durch eine neue ersetzt wird.
Hier ist ein einfaches Beispiel für eine lesende Stage.
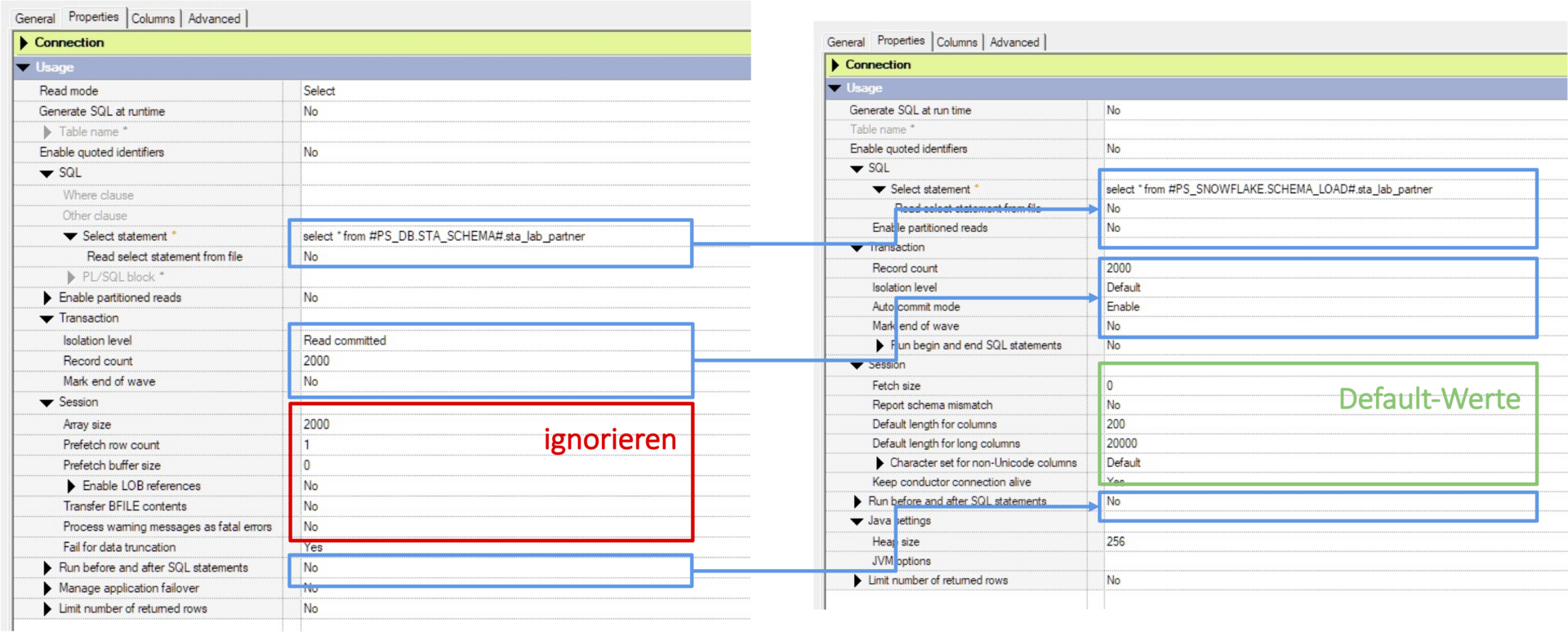
Im Falle einer manuellen Umstellung sind folgende Schritte sukzessive abzuarbeiten:
- Merke dir die Einstellungen der aktuellen Stage.
- Entferne die aktuelle Stage.
- Füge die neue Stage ein und verbinde sie mit den bestehenden Links.
- Konfiguriere die Stage:
- Übernehme die Einstellungen von der alten Stage, die unverändert übernommen werden können (in Bild blau).
- Übernehme Einstellungen von der alten Stage und passe sie an.
- Setze einige Einstellungen, die es so nur bei der Snowflake ConnectorStage gibt (im Bild grün).
Diese Schritte (und noch viel mehr) führt der JobManipulator für dich in hunderten von Jobs für tausende von Stages aus.
Fazit
- Manuell sind diese Änderungen extrem eintönig und sehr aufwendig. Das Risiko ist hoch, dass diese Arbeit sehr fehlerträchtig ist.
- Deshalb die dringende Empfehlung: Setzt die Jobs maschinell um.
Job-Migration mit dem JobManipulator
Der ITGAIN JobManipulator ist dafür ausgelegt, viele Jobs auf einmal umzustellen. Er arbeitet auf der Basis einer ISX-Datei des aktuellen Jobdesigns, die mithilfe des istools oder dem Information-Server Manager erstellt wird. Als Ergebnis wird eine neue ISX-Datei geschrieben. Der JobManipulator kann so konfiguriert werden, dass er die erzeugte Datei gleich in das Zielprojekt importiert. Falls er unter Windows aufgerufen wird, können die enthaltenen Jobs und Sequenzen gleich kompiliert werden.
Die Ausgangs-ISX-Datei kann ein ganzes Projekt (Jobs, Sequenzen, TableDefinitions, Routinen, ParameterSets usw.) oder nur Teile daraus enthalten. Binaries werden durch den JobManipulator aus der ISX-Datei entfernt.
Gesteuert wird der JobManipulator über eine JSON-Datei, in der verschiede Einstellungen vorgenommen werden.
Bis auf eine Art der Textersetzung, die komplett in einer ISX-Datei ausgeführt wird, werden grundsätzlich nur Parallel Jobs und Parallel Shared Container umgestellt. Über Filterbedingungen kann getrennt für lesende und schreibende Stages festgelegt werden, welche Jobs und darin welche Stages umgestellt werden. Es kann auf Stage-Ebene nach SQL-Schemanamen gefiltert werden. Durch die Filter kann auch dafür gesorgt werden, dass gezielt Stages unverändert bleiben.
Müssen unterschiedliche Einstellungen genutzt werden, kann der JobManipulator mehrfach für eine ISX-Datei aufgerufen werden, um sukzessive die Manipulationen auszuführen.
Im JDBC-Connect-String sind Informationen wie die das Snowflake Virtual Warehouse, eine Rolle oder ein Default-Schema enthalte. Deswegen kann es, je nachdem ob es sich um eine lesende oder schreibende ConnectorStage handelt, notwendig sein sie unterschiedliche umzustellen. Und das bedeutet, dass man unterschiedliche Einstellungen für den JobManipulator benötigt.
Features
Viele Einstellungen können direkt aus der Oracle in die Snowflake ConnectorStage übernommen werden. Insbesondere gehören dazu:
- Modus: Insert, Update, Delete, Select, Load from File
- Unterstützung des Merge-Modus, wenn das SQL durch DataStage generiert wird
- Übernahme des manuellen SQLs bzw. des Eintrags zum Tabellennamen
- RCP-Einstellung für Ausgabelinks
- Einstellung Drop Unmatched Fields
Setzen einiger Einstellungen:
- Snowflake Connect-Informationen
- Session-Parameter
- Java-Einstellungen
- Einstellungen bei Load from file und wenn der Merge-Modus genutzt wird
- Optional ein INSERT in einen Load from file umstellen.
Entfernen von Reject-Links und davon direkt abhängige Links und Stages
Anpassen der Before/After und Before/After Node SQL Statements:
- Übernehmen aus der Quelle
- Löschen des Eintrages
- Einen festen Inhalt in einen Eintrag schreiben
Es können Filterbedingungen getrennt für lesende oder schreibende Stages gesetzt werden, um nur bestimmte Stages bzw. Jobs umzustellen:
- Positivliste über SQL-Schema Namen
- Negativliste über den Stage-Namen-Prefix
Umgestellten Stages können über regex umbenannt werden.
Es können allgemein Zeichenketten über regex-Ausdrücke umgestellt werden:
- Nur in umgestellten Jobs
- In der verarbeiteten ISX-Datei
Es gibt eine Möglichkeit, SQL-Ausdrücken in lesenden oder schreibenden Stages zu manipulieren:
- Ersetzen von Zeichenketten
- Ersetzen von Funktionen
Im Folgenden schauen wir beispielhaft (nur) vier Features genauer an, damit du sehen kannst, was mit dem JobManipulator möglich ist.
Reject Links
Da die Snowflake ConnectorStage keine Reject-Links unterstützt, entfernt der JobManipulator von umgestellten Stages den Reject-Link und alle direkt davon abhängigen Stages und Links. Es bleiben nur die Job-Bestandteile stehen, die nicht direkt von einem Reject-Link abhängig sind.
Hier ist ein interessantes Beispiel, in dem der JobManipulator auch eine komplexe Reject-Verarbeitung komplett entfernen kann.
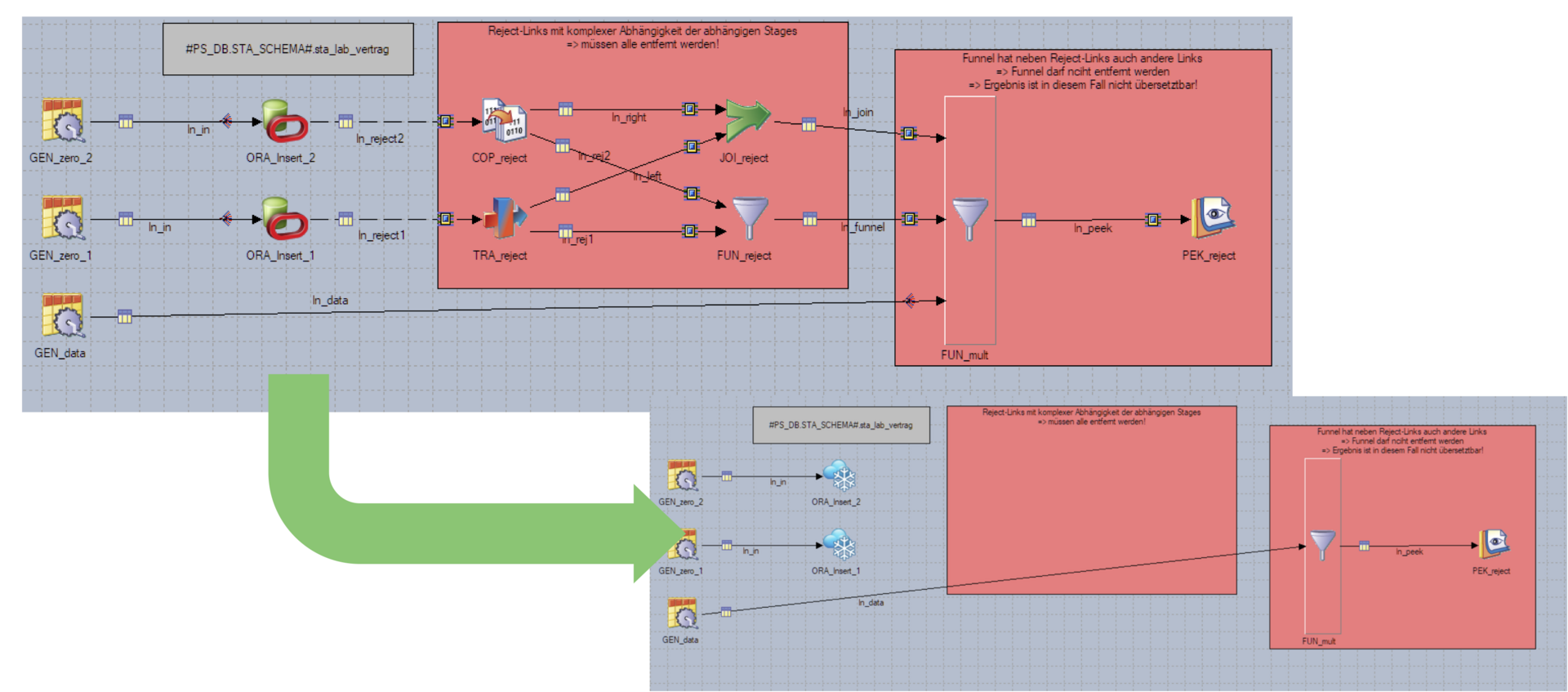
Nachdem eine Reject-Verarbeitung in einem Job entfernt wurde, kann es vorkommen, dass der Job dann nicht mehr übersetzt werden kann. Das ist in diesem Beispiel der Fall: Der letzte Funnel hat nur einen Eingabelink, der unabhängig von der Reject-Verarbeitung gewesen ist.
Hinweis: Solche Fälle sind uns bei realen ETL-Jobs aber nur sehr selten begegnet.
Textersetzung
Hier sind zwei Beispiele für Textersetzungen:
Stellt in der ISX-Datei jeden Text „JB_“ nach „“GEN_JB_“ um.
"ReplaceIsx":
{ "JB_": "GEN_JB_"
}
Damit wird nur in umgestellten Jobs das „sysdate“ case-unabhängig in einen anderen Text umgestellt.
"ReplaceJob":
{ "(?i)sysdate": " to_timestamp_ntz(current_timestamp())"
}
SQL-Manipulationen
Der JobManipulator kann SQL-Anweisungen von lesenden oder schreibenden SQL-Befehlen und in before/after SQL-Anweisungen anpassen. Es gibt Textersetzungen und Funktionsersetzungen.
Mit diesem Beispiel finden zwei Text- und eine Funktionsersetzung statt. Der letzte Parameter OrOperatorAdjustment sorgt dafür, dass der JobManipulator die Verkettung von Zeichenketten mittels || bearbeitet.
, "SqlManipulation":
{ "ReplaceSql":
{ "(?im)ALTER(.)$": "--ALTER $1"
, "#PS_DB.STA_SCHEMA#": "MY_NEW_SCHEMA"
}
, "FunctionExtension":
{ "CONCAT($1, $2)": "CONCAT(nvl($1, ''), nvl($2, ''))"
}
, "OrOperatorAdjustment": "true"
}
Die erste Textersetzung sucht nach ALTER-Anweisungen und kommentiert sie aus. Das ist insbesondere in den before/after SQL-Anweisungen sinnvoll, da über diese Anweisungen bei Oracle Admin-SQL genutzt wird.
Die zweite Textersetzung ist einfach eine Änderung eines Schema-Namens im SQL.
Die Funktionsersetzung CONCAT() ist zusammen mit OrOperatorAdjustment notwendig, da Oracle und Snowflake leere Zeichenketten unterschiedlich behandeln (s.a. Teil 5 in dieser Reihe).
before/after SQL
In der ConnectorStage können vier verschiedene before/after SQL-Anweisungen definiert werden. Diese Anweisungen werden vor bzw. nach der eigentlichen SQL-Verarbeitung ausgeführt. Der Job-Manipulator erlaubt, diese Anweisungen zu bearbeiten.
In dem folgenden Beispiel werden alle vier Möglichkeiten gezeigt, die pro Anweisung möglich sind.
Beispiel
"BeforeAfterSql":
{ "beforeSql": "(clear)"
, "afterSql": "(manipulation)"
, "beforeSqlNode": "ALTER SESSION SET QUERY_TAG = 'XO(DSJobDefSDO/@name)';"
, "afterSqlNode": ""
}
Erklärung
- Das beforeSql wird gelöscht.
- Das afterSql wird gemäß der SQL-Manipulationsregeln ReplaceSql bearbeitet. Das ist eine gute Möglichkeit, um Verwaltungs-SQL zu bearbeiten. Also beispielsweise ALTER oder CALL Anweisungen auszukommentieren, die normalerweise aufgerufen werden, um Statistiken zu sammeln oder Indizes zu aktualisieren.
- Das beforeSqlNode wird auf diesen Ausdruck gesetzt. Über den speziellen Ausdruck XO(DSJobDefSDO/@name wird im JobManipulator auf den Job-Namen zugegriffen und der wird so als QUERY_TAG gesetzt, um in Snowflake alle SQLs, die durch die Player-Prozesse ausgeführt werden, zu markieren.
- Das afterSqlNode wird unverändert aus der Ausgangsstage übernommen.
Hier findest du die anderen Teile dieser Blogserie
1 - Umzug eines DWH auf eine Snowflake
3 - Wie bindet man DataStage an?
4 - Wie erfolgt die Migration von DataStage ETL-Jobs
5 - Lasst uns in die Snowflake abtauchen
6 - Wichtige Details bei der Anbindung von DataStage an Snowflake