Wichtige Details bei der Anbindung von DataStage an Snowflake | Umzug eines DWH auf eine Snowflake - Teil 6
In diesem letzten Teil der Blogreihe über einen Umzug von Oracle zu Snowflake wollen wir uns genauer die Besonderheiten in Jobs ansehen, auf die du bei der Anpassung der DataStage Jobs achten musst.
Partitioned Read
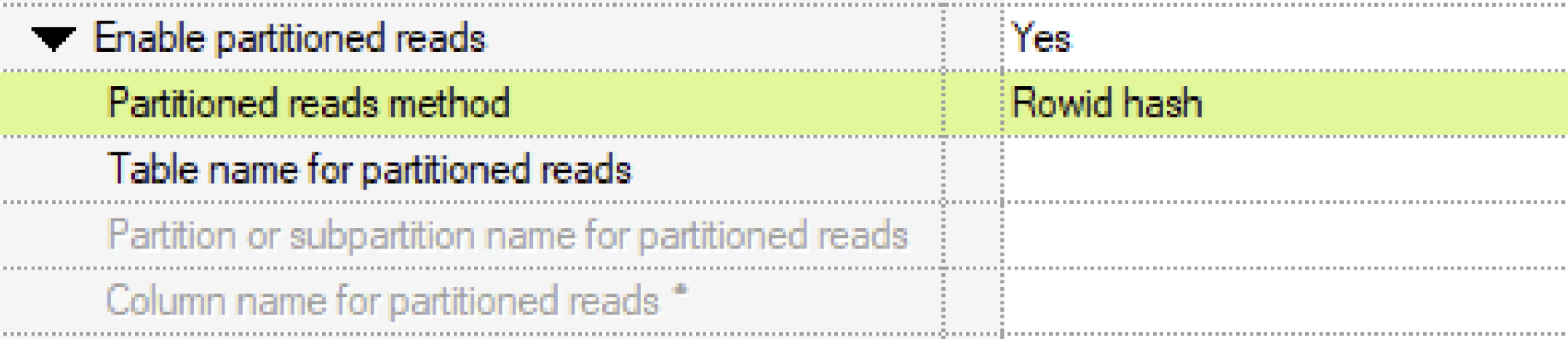
Bei einer Oracle ConnectorStage gibt es bei einer lesenden Stage die Einstellung „Enable partitioned reads“. Wird das gesetzt und gibt man beispielsweise eine „Partitioned reads method“ von „Rowid hash“ an, wird diese Stage mehrfach gestartet, um den lesenden Durchsatz zu erhöhen.
Pro Node aus der APT_CONFIG_FILE wird ein lesender Prozess gestartet und das SQL wird in der WHERE-Bedingung modifiziert:
MOD(ROWID, [[node-count]]) = [[node-number]]
[[node-count]] ist die Anzahl der Knoten
[[node-number]] gibt die Node an, auf der die Stage gestartet wird
Es gibt Fälle, wo so die lesende Performance sehr erhöht werden kann. Dieses Verfahren gibt es auch für andere ConnectorStages wie Db2, den generischen JDBC Connector und auch für die Snowflake.
Bei Snowflake gibt es keine ROWID und zudem unterstützt die Snowflake ConnectorStage hier keine weitere Parametrisierung:
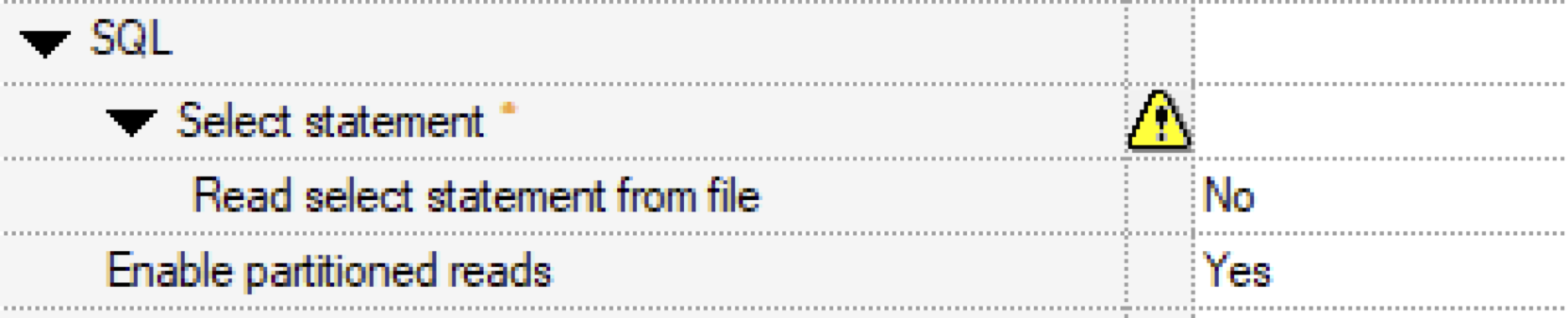
Du kannst diesen Parameter aktivieren, aber dann musst da das SQL selber um die notwendigen Anweisungen erweitern.
Link: https://www.ibm.com/docs/en/iis/11.7?topic=r-partitioned-reads-1

Warum ist das bei der Job-Migration relevant?
Würde bei der Job-Migration die Einstellungen der Stage weitestgehend 1:1 übernommen werden, so würde die Snowflake Stage Partitioned Reads machen. Da das SQL durch die ConnectorStage zur Laufzeit aber nicht angepasst wird, wird das SQL identisch mehrfach ausgeführt! Das kannst du in einem Testjob auch sehen!
Im JobManipulator setzen wir deshalb als Standard die Einstellung „Enable partitioned reads“ auf „false“.
DataStage Runtime Column Propagation (RCP)
In der aktuellen Version der Snowflake ConnectorStage gibt es endlich die Einstellung „Generate all columns as Unicode“, sodass bei RCP alle Textspalten als UNICODE generiert werden.

Bei DataStage ist der Standard „No“. Das ist leider schade, da ein „Yes“ sinnvoller wäre. Mit dieser Einstellung gibt es weniger Probleme mit Spalten, die Umlaute enthalten und/oder Sonderzeichen, die in UTF-8 mehr als ein Byte benötigen. Das gilt für Oracle genauso wie für Snowflake.
Beim JobManipulator wird deshalb die Einstellung „Generate all columns as Unicode“ auf „Yes“ gesetzt, wenn RCP auf dem Ausgabelink aktiviert ist.
LOAD, Merge, CSV-Dateien „and all that Jazz“
In Teil 3 hatten wir schon erwähnt, dass DataStage bei einer Snowflake wie bei anderen nativen Datenbank ConnectorStages auch einen „Load from file“ Modus unterstützt.
Die Parametrisierung ist ähnlich wie bei den anderen ConnectorStages, es gibt aber ein paar Besonderheiten:
- Zum einen kann und muss(!) das Format der temporär erzeugten Dateien, die auf dem Server geschrieben und dann per Snowflake PUT-Befehl hochgeladen werden, gesteuert werden.
- Zum anderen stellt DataStage eine Variante des „Load from file“ Schreibmodus bereit, die das Performance-Problem der single-row UPDATE/DELETE Befehle beheben kann: „Use merge statement = Yes“
Parametrisierung des LOAD
Hier ist ein beispielhafter Aufruf in der Snowflake ConnectorStage im „Load from file“ Modus:
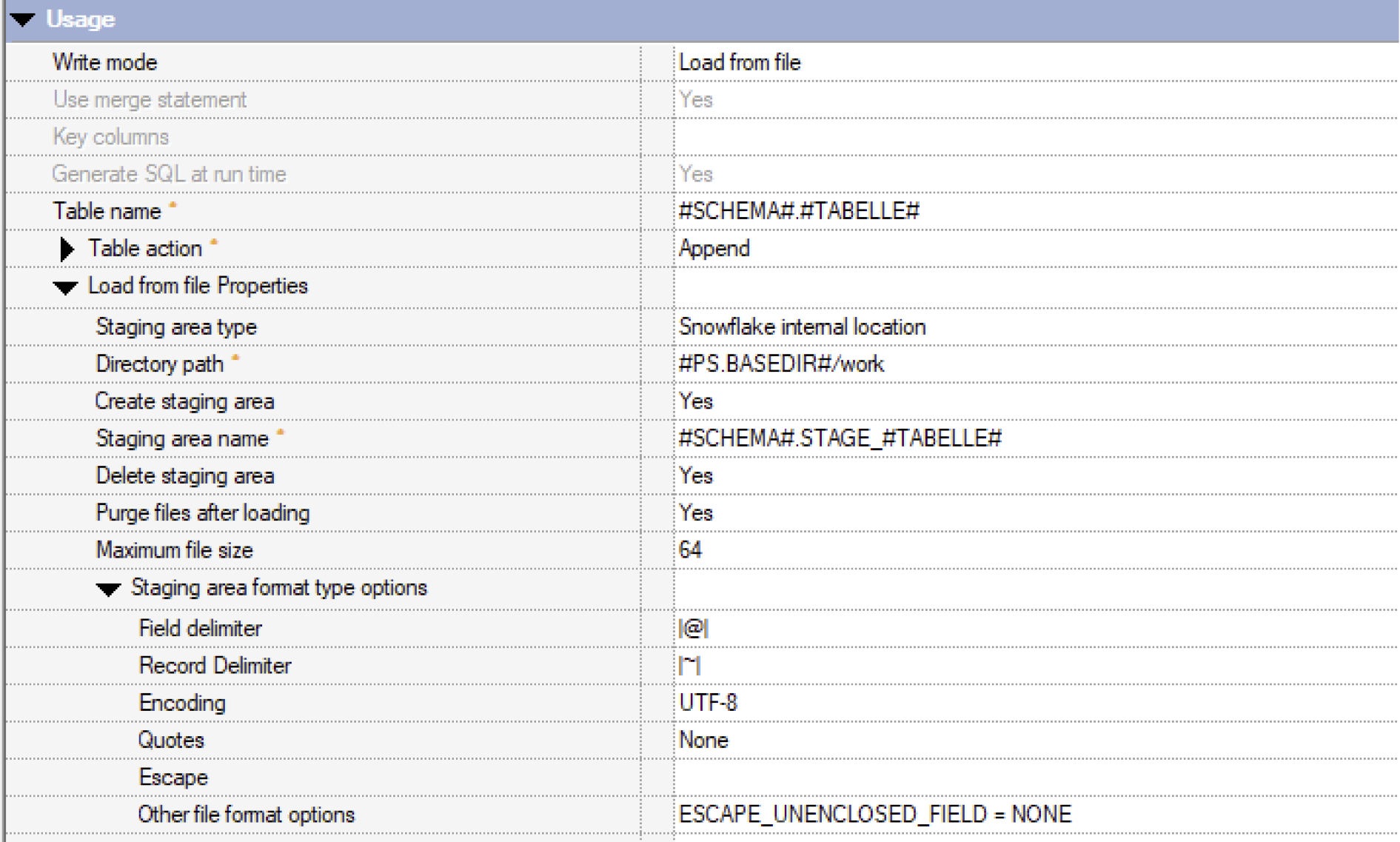
In den „Load from file Properties“ kannst du sehen, wie du die INTERNAL STAGE ansprichst. In DataStage wird das „Snowflake internal location“ bzw. „staging area“ genannt. Es ist beides Mal das gleiche und bezeichnet eine INTERNAL STAGE von Snowflake.
Format der CSV-Dateien
Der Parameter „Stage area format type options“ steuert das Format der Zwischendatei. Die Dateien sind einfache Dateien (analog zu CSV-Dateien), die einen „Field delimiter“ als Trennzeichen für Spalten und „Record Delimiter“ als Trennzeichen für Sätze nutzen.

Erst mit DataStage V11.7.1.1 wurde die Snowflake Connector Stage so erweitert, dass die ConnectorStage Daten in eine Snowflake laden kann und das Dateiformat der Zwischendatei beeinflussen kann.
Tipps:
- Die in der Abbildung (oben) angegebenen Werte für die Delimiter haben sich bewährt. Glücklicherweise können hier mehrere Zeichen als Delimiter genutzt werden, um sicherzustellen, dass diese garantiert nicht in den Daten vorkommen.
- Snowflake nutzt zwei verschiedene Einstellungen für ein Escape-Zeichen. Es sollten beide gelöscht werden. Deswegen ist „Escape“ leer und die Einstellung unter „Other file format options“ eingetragen.
Der Parameter „Maximum file size“ erscheint nur in der Connector Stage, wenn du folgenden PMR eingespielt hast: https://www.ibm.com/support/pages/apar/JR62815. Damit werden dann mehrere kleine Dateien geschrieben und die Snowflake kann PUT-Befehl besser abarbeiten. Die Praxis hat gezeigt, dass es sehr sinnvoll ist, diesen PMR einzuspielen und kleinere Dateien zu generieren!
Mehr zu den Optionen für CSV-Dateien stehen in der Snowflake Dokumentation.
Link: https://docs.snowflake.com/en/sql-reference/sql/create-file-format.html#type-csv
Parameter “Use merge statement”
Dieser Parameter ist ebenfalls erst ab dem DataStage Release V11.7.1.1 verfügbar. Er verbindet den Schreibmodus „Load from file“ mit normalen SQL-Befehlen, um Daten in der Zieltabelle sehr performant zu verändern.
Beim „Load from file“ arbeitet DataStage mit einer INTERNAL STAGE in Snowflake. Snowflake behandelt die INTERNAL STAGE wie eine Tabelle. Also kannst du aus der INTERNAL STAGE heraus nicht nur Daten mittels COPY INTO in die Zieltabelle kopieren, sondern du kannst auch mit den SQL-Befehlen wie UPDATE, DELETE oder MERGE arbeiten.
Dieser Schreibmodus kann nur eingeschaltet werden, wenn das SQL durch DataStage generiert wird. Nur dann ist es möglich bei UPDATE oder DELETE die Einstellung „Use merge statement“ auf „Yes“ zu setzen.

Ist der Parameter aktiviert, werden die Daten vom Link nicht direkt in die Zieltabelle geschrieben, sondern analog zum Schreibmodus „Load from file“ verarbeitet.
Also noch mal kurz zusammengefasst:
- Die Daten vom Link werden in eine temporäre Datei auf dem Server geschrieben und dann per PUT in eine INTERNAL STAGE von Snowflake geladen.
- Dann werden diese Daten mittels eines SQL-Befehls von der INTERNAL STAGE in die Zieltabelle übertragen.
- Abhängig vom Schreibmodus generiert DataStage dann den notwendigen SQL-Befehl: DELETE, UPDATE oder MERGE.
Der JobManipulator stellt die Snowflake ConnectorStage auf den Schreibmodus „Use merge statement = Yes“, wenn die Stage generiertes SQL nutzt.
Handling des Oracle-Schreibmodus „Insert new rows only“
Bei der Oracle ConnectorStage führt dieser Modus dazu, dass Daten per INSERT eingefügt werden und wenn es eine Verletzung eines UNIQUE Constraints gibt, wird dieser Satz ignoriert.
Die Snowflake ConnectorStage erlaubt keinen Schreibmodus „Insert new rows only“. Da Snowflake keinen Unique-Constraint anwendet, können problemlos ohne Vorkehrung doppelte Datensätze/Keys in die Tabelle geschrieben werden!
Bei der Snowflake gibt es zwei andere Schreibmodi, die stattdessen genutzt werden könnten. Allerdings erzeugen sie einen anderen Datenstand als unter Oracle und es müssen Key-Felder definiert werden!
- „Insert then Update“: Dahinter steht ein MERGE-Befehl, der Daten einfügt, oder falls sie schon existieren, ändert.
- „Delete then Insert“: In der Zieltabelle werden die Daten über den KEY gesucht und gelöscht und dann neu eingefügt.
Es gibt auch noch den „Insert Overwrite“ Modus, aber Vorsicht: da wird vor dem INSERT ein TRUNACTE durchgeführt!
Snowflake: https://docs.snowflake.com/en/sql-reference/sql/insert.html

Der Schreibmodus „Insert news rows only“ kann nicht automatisiert umgestellt werden. Die beiden Schreibmodi bei Snowflake erzeugen einen anderen Datenstand! Der Job muss analysiert und dann idealerweise vor der Migration so angepasst werden, dass er auf diesen Modus verzichtet. Nur dann kann er automatisiert umgestellt werden.
Der JobManipulator setzt den Modus „Insert new rows only“ auf „Insert“ um und gibt eine Warnung im Protokoll aus.
Schätzchen in DataStage Jobs
Und dann gibt es immer wieder besondere, unerwartete „Schätzchen“ in DataStage Jobs. In der Regel werden die Jobs manuell erstellt und dann als „fertig“ betrachtet, wenn der Job das tut, was er tun soll.
Aber das heißt nicht, dass das, was da gebaut wurde, „gut“ ist und in allen denkbaren Konstellationen sich so verhält, wie der Entwickler es erwartet. Leider fällt so eine Implementierung erst bei einem Umzug auf die Füße. Manchmal liegt es an einem Upgrade der DataStage Version (wir schauen dich an: verändertes NULL-Handling im Transformer), manchmal sind es Funktionen, die in der einen Umgebung „funktionieren“ und in der anderen nicht.
Beispiel: Zuordnung von SELECT-Spalten zu Link-Spalten
Im Folgenden wird ein Beispiel für so ein Schätzchen aufgeführt. Es wird dadurch ausgelöst, dass die Oracle ConnectorStage eine unsaubere Job-Erstellung erlaubt und im produktiven Betrieb auch „funktioniert“
Das „Schätzchen“ liegt daran,
- dass die Oracle ConnectorStage beim Lesen es erlaubt, dass die Spalten auf dem Link einen anderen Namen haben können als in der Ergebnismenge vom SQL,
- und die Snowflake ConnectorStage erlaubt das nicht.
Das hört sich jetzt vielleicht einfach an, es ist aber komplizierter. (Oder es hört sich kompliziert an, dabei ist es doch eigentlich ganz einfach).
Ausgangslage:
- Wenn eine lesende ConnectorStage ein SELECT ausführt, besteht die Ergebnismenge aus Zeilen und Spalten.
- Der Ausgabelink der ConnectorStage hat auch eine gewisse Anzahl von Spalten.
Zur Laufzeit muss die ConnectorStage die Spalten vom SQL zu den Spalten auf dem Link zuordnen.
- Entweder erfolgt es über den Spaltennamen,
- Oder über die Position im Ergebnis
Problemstellung:
Hier unterscheiden sich die Oracle und die Snowflake ConnectorStage stark!
Oracle
- Wenn die Oracle-Stage zu einer Ergebnisspalte keine Zuordnung über den Namen machen kann, fällt sie komplett auf den Modus zurück, wo die Daten über die Reihenfolge der Spalte zugewiesen werden.
- Also: Die erste Ergebnisspalte geht in die erste Spalte vom Link; die zweite in die zweite usw.
- Die Namen der Spalten werden dann nicht mehr berücksichtigt, selbst wenn es noch einzelne Übereinstimmungen gibt.
Snowflake
- Die Snowflake ConnectorStage macht nur eine Zuordnung über den Spaltennamen. Wenn es keine Übereinstimmung gibt, bricht die Verarbeitung ab!
Dieses Beispiel kann leider nur durch eine manuelle Anpassung vor der Migration gelöst werden. Es gibt hierfür keine automatisierte Unterstützung.
Fazit
Besondere „Schätzchen“ kann es immer geben. Du kannst nur nach solchen "Schätzchen“ suchen, wenn du sie kennst oder ahnst, wo sie versteckt sein könnten. Also du oder „jemand anderes“ ist im Vorfeld darüber gestolpert.
Das Schätzchen, dass die Ergebnismenge eines lesenden SQL nicht zum Ausgabelink passt, führt zu erhöhten manuellen Aufwänden. Das kann leider nicht maschinell umgesetzt werden.
Hier findest du die anderen Teile dieser Blogserie
1 - Umzug eines DWH auf eine Snowflake
3 - Wie bindet man DataStage an?
4 - Wie erfolgt die Migration von DataStage ETL-Jobs
5 - Lasst uns in die Snowflake abtauchen
6 - Wichtige Details bei der Anbindung von DataStage an Snowflake