
Überblick und Grundlagen | Umzug eines DWH auf eine Snowflake - Teil 2
Es geht hier um einen Umzug der Daten einer Data Warehouse Anwendung von einer on-premise Oracle Datenbank auf eine cloudbasierte Snowflake Datenbank. Die Anwendung hat einen großen (klassischen) ETL-Kern basierend auf IBM DataStage, der auch weiterhin als on-premise Anwendung betrieben werden soll. Im Ergebnis haben wir nach der Umstellung einen hybriden Betrieb.
Wir fokussieren uns auf das Data Warehouse und vor allem auf seine Bewirtschaftungsprozesse. Im Rahmen einer Migration der ETL-Abläufe müssen in denDataStage Jobs die Oracle ConnectorStage durch die Snowflake JDBC ConnectorStage ausgetauscht werden. Auf die Migration der Daten gehen wir hier nur insoweit ein, als sie für die Migration des ETLs relevant ist.
By the way: einige Aspekte von Umstellungsprogrammen lassen wir bewusst aus: Die Migration des Berichtswesens auf das neue RBMS und Belieferung abnehmender Systeme wären eine eigene Blog-Reihe wert, ebenso das Thema Security, die Netzwerk-Aspekte und einiges mehr.
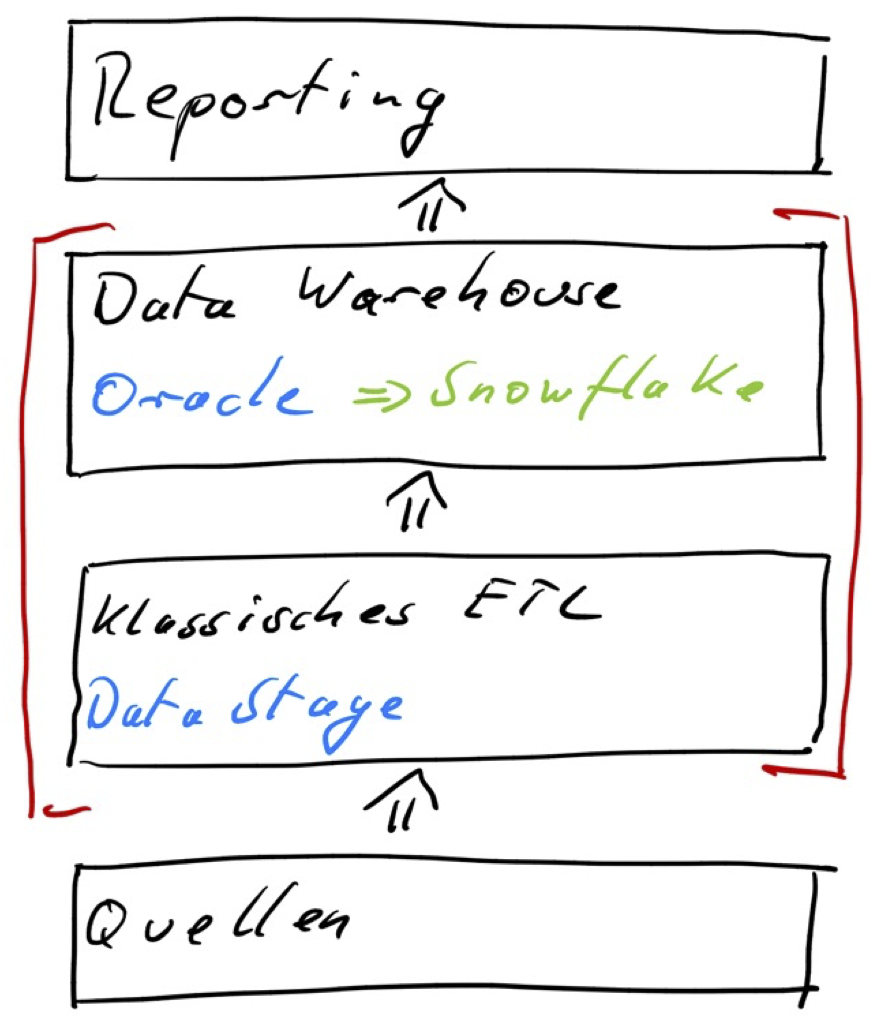
Migration der ETL Abläufe
Ziehen die Daten auf ein anderes RDBMS um, müssen in der Regel auch die ETL-Abläufe anpasst werden. Neben dem eigentlichen (mechanischen) Vorgang der Job-Anpassung gibt es ein paar Punkte, die du dir im Vorfeld klarmachen musst:
- Was ist, wenn das alte ETL Fehler enthält, die erst nach Beginn der Migration entdeckt werden? Willst du Fehler migrieren?
- Was ist, wenn ein Feature der alten Umgebung genutzt wurde, dass keine Entsprechung in der neuen Umgebung hat?
- Und was ist mit den ganzen „Schätzchen“, die sich in alten, vielleicht schon lange nicht mehr angesehenen Job-Abläufen versteckt haben?
Unterschiedliche RDBMS-Produkte und unterschiedliche Features in den Connector-Stages von Oracle und Snowflake resultieren in einem veränderten Job-Verhalten, auf die das Migrationsteam zwingend reagieren muss! In den letzten beiden Blog-Beiträgen werden wir beispielhaft ein paar Aspekte des veränderten Verhaltens genauer ansehen. Aber auch das sind nur Beispiele. Das muss längst nicht alles sein und kann sich auch von Umgebung zu Umgebung unterscheiden.
Zu Beginn wird es immer wieder unklare Punkte geben und du wirst Ursachenforschung betreiben:
- Ist es ein Problem bei der Job-Umstellung?
- Ist es ein Problem in der Zusammenarbeit von DataStage und Snowflake?
- Gibt es ein Fehler im SQL aufgrund unterschiedlicher Dialekte von Oracle und Snowflake?
- Liegt der Fehler in den Daten oder den Abläufen? Gab es den Fehler schon vor der Job-Migration, oder ist er erst danach eingebaut worden?
- Du solltest dir unter Umständen auch die Frage stellen, ob du vielleicht falsche Erwartungen hattest, z.B. in Performanceaspekten.
Du wirst zu Beginn viel lernen müssen:
- Wenn du vorher noch nie mit einer Snowflake gearbeitet hast, solltest du zuerst unbedingt mit der Snowflake Erfahrungen sammeln.
- Entwickle eine Strategie, um die Jobs umzustellen.
- Lerne, wie die Kombination DataStage und Snowflake funktioniert.
- Und ja, Du wirst auch lernen den JobManipulator zu bedienen – ganz ehrlich, das wird das geringste Problemchen sein.
…und dann gibt es noch die beiden wichtigen Fragen:
- Welche Änderungen gehen maschinell/automatisiert – mit dem JobManipulator?
- Welche Änderungen müssen manuell durchgeführt werden?
Maschinelle Migration von ETL-Abläufen
Eine maschinelle und automatisierte Migration von ETL-Abläufen sollte über eine Konfiguration gesteuert werden. Idealerweise sollten dann kein weiterer manueller Eingriff mehr benötigt werden. Alles Wichtige steckt in der Konfiguration. Sie sollte so allgemeingültig wie möglich eingestellt werden können. Du möchtest nicht für jeden Job einzeln die Konfiguration vornehmen. Damit erreichst du, dass diese Migration beliebig häufig aufgerufen werden kann. Der (manuelle) Aufwand steckt darin, die richtige Konfiguration zu finden und sie zu testen.
Eine Migration kann trotz aller Umsicht fehlerhaft ablaufen. Wenn der Fehler gefunden wurde, kann die maschinellen/automatisierte Änderung schnell und einfach wiederholt werden.
Bei einer maschinellen Änderung ist es bzgl. Aufwand nahezu egal, ob sie einmal oder tausendmal ausgeführt wird!
Leider werden sich manuelle Änderungen trotzdem nicht vermeiden lassen. Das haben wir insbesondere beim SQL erfahren. SQL-Befehle lassen sich (auch mit den Mitteln vom JobManipulator) nicht immer komplett maschinell umsetzen. Die Feinheiten der Unterschiede (später mehr) in den SQL-Dialekten und eventuelle „Schätzchen“, die sich auch in SQL-Befehlen verstecken können, erzwingen manchmal ein manuelles Eingreifen.
Manuelle Änderungen
Jede manuelle Änderung ist fehlerträchtig. Je mehr manuelle Änderungen ausgeführt werden müssen und je repetitiver und/oder stupider diese Änderungen sind, desto höher wird die Fehlerrate sein. Beides zieht erhöhte Test- und Korrekturaufwände nach sich.
Unterschätze nicht den Aufwand, den eine manuelle Umstellung von Jobs bringt. Gerade die stupide und stumpfe Änderung von hunderten von Jobs (Oracle ConnectorStage raus, Snowflake ConnectorStage rein), ist sehr fehleranfällig! Lerne die Vorzüge der konfigurationsgetriebenen Automation schätzen.
Fazit
Jeder Umzug (außer er ist sehr trivial) umfasst Änderungen an den Abläufen und Daten. Das sollte von Anfang eingeplant werden:
- Rechne mit Überraschungen: Tests werden dir zeigen, dass du doch mehr ändern musst, als du vorher vielleicht gedacht hattest. Plane deshalb reichlich Zeit zum Testen ein.
- Plane Puffer ein: Du wirst häufiger Jobs erneut konvertieren müssen, weil dein erster Ansatz nicht alle Job- und Daten-Konstellationen abdeckt.
- Automatisiere, soviel es geht: Du erreichst damit eine gleichbleibend hohe Qualität und zugleich eine hohe Geschwindigkeit.
- Start „Small“: Migriere erst mal wenige, aber wichtige oder typische Abläufe.
- Finish „Big“: Migriere große, komplexe Projekte später, wenn du mehr Erfahrungen gesammelt hast.
Die Snowflake ist anders!
In diesem Kapitel geben wir erste Hinweise, warum es für das inhouse Team so wichtig ist, selbst zu agieren und Erfahrungen zu sammeln: Die Snowflake ist eine analytische Datenbank. Sie hat einen anderen Fokus als eine klassisches RDBMS wie Oracle oder Db2, die aus der transaktionalen operativen Welt hervorgegangen sind.
Das führt zu Besonderheiten: Das Projektteam muss diese kennen, damit es die Anwendung darauf trimmen kann. Andernfalls gibt es böse Überraschungen, funktional wie in der Performance.
Speicherung der Daten
Die physikalische Speicherung der Daten ist in der Snowflake völlig anders. Es gibt keine Tablespaces oder Partitionen! Die vielen Parameter bei einem CREATE TABLE, um die Organisation oder Speicherung zu beeinflussen, fallen ersatzlos weg.
Du musst dir auch keine Gedanken über Partitionierungen oder das Verteilen der Daten auf unterschiedliche Storage-Nodes machen. Das erledigt die Snowflake eigenständig unter der Haube.
Link: https://docs.snowflake.com/en/user-guide/tables-clustering-micropartitions.html
Zwischenfazit
- Alle Bestandteile in den vorhandenen Abläufen, die sich mit der Verwaltung dieser technischen Datenbankobjekte beschäftigt, müssen entfernt werden.
INSERT/UPDATE/DELETE
Als analytische relationale Datenbank bietet Snowflake natürlich „normale“ INSERT/UPLDATE/DELETE Befehle an, um einzelne Daten einzufügen oder zu verändern. Das ist notwendig, um einige SQL-Standards einzuhalten.
Die Snowflake ist für ELT-Operationen optimiert: Es sollten also viele Daten mit einem Aufruf verarbeitet werden. Sie ist (aktuell) nicht für OLTP-Systeme konzipiert.
Die Performance von single-row SQL-Befehlen ist sehr(!) gering. Bei UPDATE und DELETE liegt sie bei ca. 1 row/s oder schlechter.
JA! Du hast richtig gelesen: 1 Zeile pro Sekunde!
Hier ist ein DataStage Test-Job, der ein paar Sätze generiert und dann per UPDATE in eine Zieltabelle schreibt. Hier liegt kein Konfigurationsfehler vor! Es liegt nicht an DataStage. Eine vergleichbare Verarbeitung mit Python oder Java liefert die gleiche „Performance“.

By the way: Wir haben auch gesehen, dass jeder nicht-triviale SQL-DML-Befehl durchaus eine minimale Laufzeit von 100ms, also 0,1s haben kann! Und das ist nur eine untere Grenze. Unabhängig vom verarbeiteten Volumen haben nicht-triviale SQLs einen nicht zu vernachlässigenden Overhead. Von on-premise Datenbanksystemen kennst du das vermutlich nicht.
Es gibt noch größere Ausreißer. Bei sehr komplexem SQL kann die Bestimmung des Ausführungsplans schon mal mehrere Minuten dauern! Wir haben auch derartige Fälle gesehen, der Snowflake-Support hat uns da helfen können.
Zwischenfazit
- Bei einer Snowflake gibt es im Vergleich zu Oracle oder Db2 andere Wege, um (Massen-)Daten zu laden bzw. zu verändern. Die Daten sollten in eine Zwischentabelle geschrieben und dann werden die Änderungen mittels ELT in die Zieltabelle übernommen. Dann sind auch UPDATE/DELETE/MERGE wieder schneller.
- Noch besser wäre (natürlich) eine INSERT-only Verarbeitung. Das ist dann aber eine Aufgabe für ein späteres Refactoring-Projekt.
- Bestehende UPDATE/DELETE-Verarbeitungen können nicht 1:1 umgestellt werden, da damit keine ausreichende Performance erlangt werden kann. Glücklicherweise bietet DataStage mit dem Parameter „Use merge statement“ eine Funktionalität und der JobManipulator unterstützt sie im Rahmen der automatisierten Umstellung! In Teil 3 und 6 gehen wir da genauer darauf ein.
SQL – „fehlende“ Funktionalität
Einige Funktionen oder Tools, die du von deiner bisherigen Datenbank her kennst, gibt es so nicht:
- PL/SQL
- Trigger
- GLOBAL TEMPORARY TABLE
- Statistiken
- Hints
- Synonyme
- Indizes
- SQL*Plus
Außer NOT NULL werden keine anderen Constraints erzwungen, wirklich keine! In Snowflake kann bei einer Tabelle ein PRIMARY KEY definiert werden, da aber kein UNIQUE Index dahintersteht, erzwingt Snowflake keine Eindeutigkeit!
Zwischenfazit
Hier können die größten Fallen liegen. In den von uns betreuten Projekten hatten wir da weniger Probleme. Auch die fehlenden CONSTRAINTS waren da weniger ein Problem. Das hängt aber stark von der jeweiligen Implementierung ab. Setzt ein Projekt beispielsweise intensiv auf TRIGGER, dann wirst du dort große Probleme haben.
SQL – „andere“ Funktionalität
Einige Funktionen erscheinen ähnlich zu sein, sind dann aber doch anders.
- Es gibt keine Reorganisation, wie in anderen Datenbanken. In einer Snowflake kann es aber den Fall geben, dass die Daten umkopiert werden müssen. In diesem Fall werden sie in eine neue Tabelle kopiert und dann die alte Tabelle gelöscht.
- Materialized Views funktionieren ganz anders!
Das Produkt Snowflake ist noch nicht so alt, dass viele dieser besonderen Funktionen jetzt schon enthalten sind. Die Zeit wird zeigen, wann sie kommen oder ob sie überhaupt kommen. Einige Funktionen sind im Rahmen einer analytischen Datenbank vielleicht auch gar nicht relevant und können anders besser gelöst werden.
Fazit
Wenn du schon lange mit einem (oder allen) der Platzhirsche im Datenbank-Markt gearbeitet hast, musst du dich umgewöhnen, wenn du auf eine analytische Datenbank schwenkst. Erst recht, wenn es eine Snowflake ist, die mittels Software-as-a-Service viele Dinge vor dem Anwender verbirgt oder besser gesagt einige lästige Dinge dem Anwender abnimmt.
Eine Snowflake ist keine Oracle, auch wenn sie von vielen ex-Oracle-Mitarbeitern geformt wurde. Das muss sich jeder immer vor Augen halten, der so einen Umzug plant. Nutze nicht die alten Konzepte und Erfahrungen, ohne nachzudenken oder zu testen!
Hier findest du die anderen Teile dieser Blogserie
1 - Umzug eines DWH auf eine Snowflake
3 - Wie bindet man DataStage an?
4 - Wie erfolgt die Migration von DataStage ETL-Jobs
5 - Lasst uns in die Snowflake abtauchen
6 - Wichtige Details bei der Anbindung von DataStage an Snowflake