
Matillion ETL - Hands On
Hat der letzte Blogartikel „Matillion ETL – Datenintegration für und in der Cloud“ dein Interesse geweckt und du kannst es kaum erwarten, deine ersten praktischen Erfahrungen mit Matillion ETL zu sammeln? Dann bist du hier genau richtig. In diesem Blogeintrag wirst du Schritt für Schritt durch den Prozess der Konfiguration einer kostenlosen Matillion-Instanz geleitet, welche als Zieldatenbank die Snowflake angebunden hat. Das Ziel ist der Aufbau einer Sandbox-Umgebung, mit welcher das Tool auf Leib und Seele getestet werden kann.
Hands On
Die Roadmap für diesen Blogartikel ist in Abbildung 1 visualisiert.
Im ersten Schritt werden die benötigten Voraussetzungen geklärt. Wie das Erstellen einer Matillion-Instanz funktioniert, wird im zweiten Schritt vorgestellt, gefolgt von einer kurzen Einführung in das User-Interface von Matillion ETL. Für einen leichten Einstieg in das Tool wird abschließend eine beispielhafte Datenstrecke vorgestellt, sodass die bestmöglichen Voraussetzungen geschaffen werden, wenn es darum geht, die ersten eigenen praktischen Erfahrungen zu sammeln.
Voraussetzungen klären
Die einzige Voraussetzung für dieses Hands On ist eine Snowflake-Instanz. Wie du eine kostenlose Snowflake-Instanz erstellst und konfigurierst, kannst du in diesem Blogartikel nachlesen.
Matillion-Instanz erstellen
Der hier aufgeführte Weg, eine Matillion-Instanz zu erstellen, erfolgt über Partner Connect von Snowflake. Über Partner Connect ist es möglich, verschiedene Anwendungen ohne viel Konfiguration in Kombination mit Snowflake zu testen. Dies ermöglicht es innerhalb weniger Minuten eine lauffähige Matillion-Instanz aufzusetzen, welche kostenlos ist und für 14 Tage besteht.
Kommen wir nun zur Erstellung einer Matillion-Instanz. Dies erfolgt über das Snowflake User-Interface. Im ersten Schritt muss die Rolle des aktuellen Users auf Account Admin umgestellt werden. Anschließend kann über das Symbol von Partner Connect das Produkt Matillion ETL ausgewählt werden. Dieses Symbol befindet sich oben rechts neben dem Hilfssymbol. Snowflake wird jetzt im Hintergrund automatisch verschiedene Konfigurationen vornehmen. Anschließend bekommt der Nutzer eine E-Mail mit den Log-in-Daten, mit welchen er direkten Zugriff auf eine soeben erstellte Matillion-Instanz erhält. Wurde die Instanz gestartet, muss nun lediglich das Projekt Snowflake ausgewählt werden. Doch bevor wir uns in die Praxis stürzen, klären wir in einem kleinen Theorieabschnitt die wichtigsten Funktionen des User-Interface, sodass der Einstieg schneller gelingen kann.
Erklärung des User-Interface
Die Abbildung 2 zeigt das User-Interface von Matillion. Hier werden noch einmal wichtige Funktionen und Fenster vorgestellt. Gehen wir diese gemeinsam einmal durch:

1. Projektmenü
Das Projektmenü beinhaltet alle Optionen rund um das Projekt, Versionierung von Jobs, Optionen zu den Environments, Import-Export Optionen sowie weitere wichtige Funktionen.
2. Navigationsfenster
Hier befinden sich die Projekte, angeordnet als Ordnerstruktur. Als kleinste Granularität befinden sich hier die verschiedenen Jobs. Prinzipiell gibt es zwei Jobarten in Matillion. Erstens den Orchestration Job in Blau (Das EL bei ELT). Dieser hat als Hauptaufgabe das Erstellen von DDL-Statements (Create, Drop und Alter) und das Laden von externen Datenquellen. Die zweite Jobart ist der Transformationsjob in Grün(Das T bei ELT): Dieser hat als Hauptaufgabe Daten zu transformieren, welche sich schon im Data Warehouse befinden. Dies beinhaltet zum Beispiel das Filtern von Daten, das Ändern der Datentypen oder das Säubern von Zeilen.
3. Job Leinwand (canvas)
Hier werden die verschiedenen Jobs modelliert, sprich die Job Leinwand ist die grafische Modellierungsoberfläche, auf welcher die Entwickler die ELT-Prozesse modellieren.
4. Komponentenfenster
Das Komponentenfenster beinhaltet alle verfügbaren Komponenten für den Workflow, welche per Drag-and-Drop auf die Leinwand gezogen werden. Die Komponentenauswahl ändert sich, je nachdem, in welchem Job sich der Entwickler befindet.
5. Shared Job Fenster
Hier können auf Shared-Job-Komponenten zugegriffen werden. Diese Komponenten erlauben es, komplette Orchestration Jobs in einer einzigen Custom-Komponente zu speichern, welche dann woanders im Projekt wiederverwendet werden kann.
6. Umgebungs-Fenster
Dieses Fenster beschreibt die Verbindung zu den Zieldatenbanken. Hier können Tabellen, welche sich in der Datenbank befinden, für den Transformationsjob per Drag-and-Drop in die Leinwand gezogen werden. Auf einer Instanz können mehrere Zieldatenbanken angebunden werden, zum Beispiel eine für Entwicklung und eine für Produktion.
7. Eigenschaftsfenster
Sobald eine Komponente selektiert wird, erscheint das Eigenschaftsfenster, in welchem Konfigurationen an den einzelnen Komponenten vorgenommen werden können.
8. Task-Fenster
Dieses zeigt Informationen über die in der aktuellen Session gelaufenen Jobs. Für sehr komplexe Jobs gibt es noch die Task Info für eine übersichtlichere Anordnung der einzelnen Tasks.
Eigene Erfahrungen sammeln
Um den Einstieg zu erleichtern, wird im Folgenden zunächst die bestehende Beispieldatenstrecke erklärt. Danach wird es leichter fallen, kleine Änderungen vorzunehmen und das Tool selbst auszuprobieren.
Die Abbildung 3 soll das Verständnis der Datenstrecke erleichtern.
Das Endziel der vorliegenden Datenstrecke ist der Aufbau einer Dimension für eine US-Flughafen-Tabelle, welche zunächst in die Stage-Schicht geladen wird und anschließend auf dem Weg in die Data-Mart-Schicht bereinigt und angereichert wird.
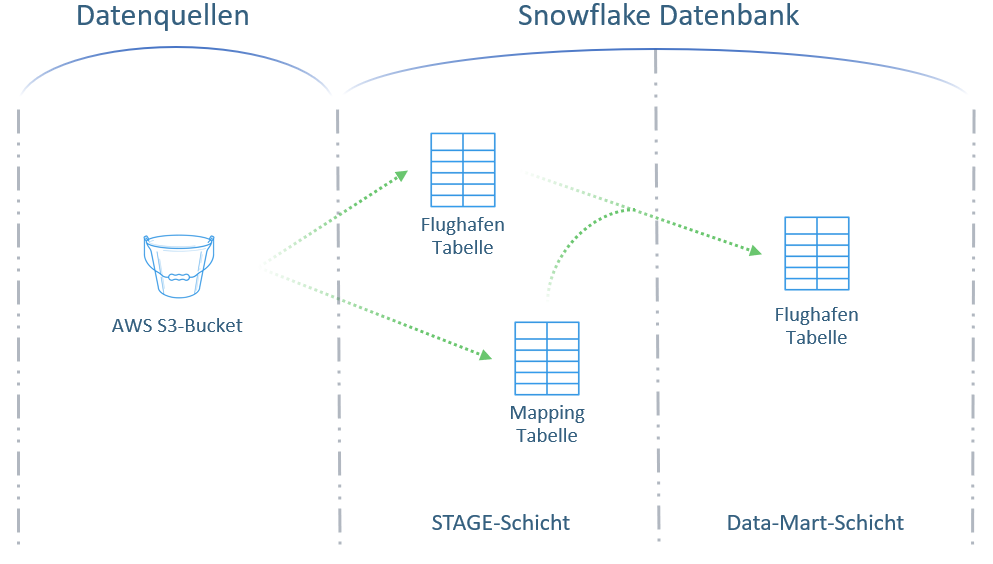
Extraktion der Daten
Als Quelle für die vorliegende Datenstrecke wird eine Flughafen-Rohdatei in JSON-Format und eine Mapping-Tabelle als CSV-Datei verwendet. Diese werden aus einem AWS S3-Bucket bezogen. Zu Beginn werden durch den Orchestration Job dim_airport_setup drei Tabellenstrukturen angelegt. Dies ist in Abbildung 3 noch einmal visualisiert. Anschließend werden zwei der soeben erstellten Tabellenstrukturen in der Stage-Schicht mit den Daten aus dem S3-Bucket beladen. Die Daten liegen also ab diesem Zeitpunkt auf der Datenbank.
Transformation der Daten
Anschließend wir der dim_airports Transformationsjob aufgerufen. Im ersten Schritt wird die auf der Datenbank liegende Flughafentabelle im AVRO-Format mit der Snowflake spezifischen Funktion Flatten Variant in ein relationales Format gebracht. Nachdem die Daten im relationalen Zustand sind, werden kleinere Bereinigungen wie das Löschen von Null werten, das Löschen von Duplikaten sowie das Einfügen eines Timestamps der Beladung hinzugefügt. Abschließend werden die Daten mit der Mapping Tabelle angereichert, sprich den Daten wird noch die ausgeschriebene Bezeichnung des US-States hinzugefügt. Anschließend wir die Tabelle in die zuvor erstellte Datenbanktabelle geschrieben. Damit ist die vorliegende ETL-Strecke abgeschlossen.
Jetzt bist du dran. Starte damit, kleinere Änderungen an der bestehenden Datenstrecke vorzunehmen. Nachdem dies gemeistert wurde, wäre der Aufbau einer eigenen Datenstrecke mit den Testdaten von Snowflake der nächste Schritt. Viel Vergnügen beim Ausprobieren.
Fazit
Falls dieser Artikel Interesse geweckt hat, folgt gerne unserer Blogserie für weitere spannende Artikel rund um BI in der Cloud. Falls es noch offene Fragen gibt, kommt gerne persönlich auf uns zu. Wir freuen uns auf einen kurzweiligen Austausch.
Hier findest du unsere weiteren Cloud-BI Blogbeiträge
(1) - Keine Schneeballschlacht mit Daten
(2) - Snowflake – Getting Started #1 Erstellung eines kostenlosen Testaccounts und Erklärung der UI
(3) - Matillion ETL – Datenintegration für und in der Cloud
(4) - Snowflake – Getting Started #2 Erstellung eines Virtual Warehouses und einer Datenbank