
Snowflake – Getting Started #2 Erstellung eines Virtual Warehouses und einer Datenbank
Willkommen zurück!
Schön, dass Du dabeigeblieben bist und nach einem ersten Überblick über das User-Interface jetzt die ersten Schritte in der Snowflake unternehmen möchtest. Reden wir gar nicht lange um den heißen Brei herum, sondern legen direkt los.
Über den Reiter Warehouses und einem Klick auf +Create können wir unsere neue Cluster-Instanz erstellen. Der Name für unser Warehouse kann frei gewählt werden. In unserem Fall wählen wir den Namen Snowflake_Blog. Als Größe für unser Warehouse wählen wir bei Size X-Small aus. Die kleinstmögliche Größe reicht für unsere rudimentären Abfragen und Datenmengen komplett aus. Wir können die Optionen eines Warehouses jederzeit anpassen, die Einstellungen sind dementsprechend nicht bindend. Weitere Informationen zu den möglichen Größen eines Warehouses können direkt unter dem Auswahlfenster der Größe gefunden werden. Dort finden wir beispielsweise weitere Details zum Pricing jeder Warehouse-Größe oder der Anzahl der Rechenkerne je Instanz.
Auto-Suspend belassen wir auf dem Standardwert von 10 Minuten. Mit dieser Option können wir die Zeit einstellen, nach der unser Warehouse in einen Ruhemodus versetzt wird, falls sie nicht genutzt wird. Wenn also in unserem Beispiel keine Abfragen oder sonstige Transaktionen innerhalb des Warehouses geschehen, wird es in den Ruhemodus versetzt, um keine weiteren Kosten zu erzeugen. Den Haken bei Auto-Resume lassen wir ausgewählt. Dadurch wird das Warehouse automatisch aktiviert und aus dem Ruhemodus geholt, sobald eine Abfrage oder Berechnung ausgeführt wird. Danach gelten erneut die 10 Minuten bis zum Ruhemodus durch Inaktivität. Als Comment geben wir unserem Warehouse einen beschreibenden Text, zum Beispiel Testwarehouse für unseren Snowflake Blog. Das Ganze sollte nun wie folgt aussehen:
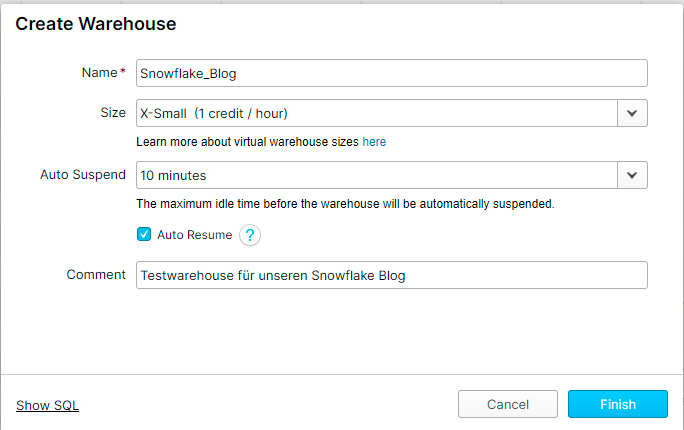
Unter Show SQL können wir uns den SQL-Befehl anschauen, welcher mit einem Klick auf Finish ausgeführt wird.
CREATE WAREHOUSE Snowflake_Blog WITH WAREHOUSE_SIZE ='XLARGE' WAREHOUSE_TYPE ='STANDARD' AUTO_SUSPEND =600 AUTO_RESUME =TRUE COMMENT ='Testwarehouse für unseren Snowflake Blog';
Mit einem Klick auf Finish wird unser neues Warehouse erzeugt und unmittelbar in unserer Übersicht aller Warehouses aufgelistet. Nachdem wir unser Virtual Warehouse erfolgreich erstellt haben, gehen wir auf den Reiter Databases. Auch hier können wir über +Create eine neue Datenbank generieren. Den Namen und Kommentar könnt Ihr frei wählen, wir nehmen SNOWFLAKE_BLOG_DB mit dem Kommentar Datenbank unseres Snowflake-Blogs.
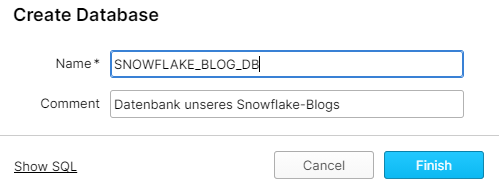
Auch hier können wir uns das generierte SQL über Show SQL anschauen.
CREATE DATABASE SNOWFLAKE_BLOG_DB COMMENT ='Datenbank unseres Snowflake-Blogs';
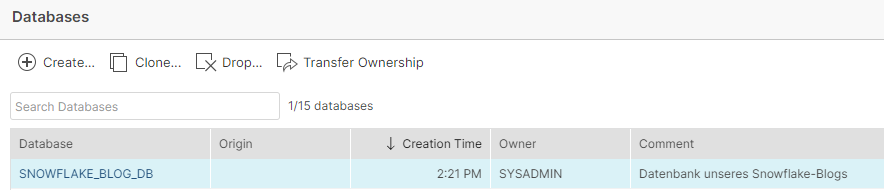
Mit Finish erstellen wir unsere Datenbank und können diese direkt in der Liste unserer Datenbanken sehen.
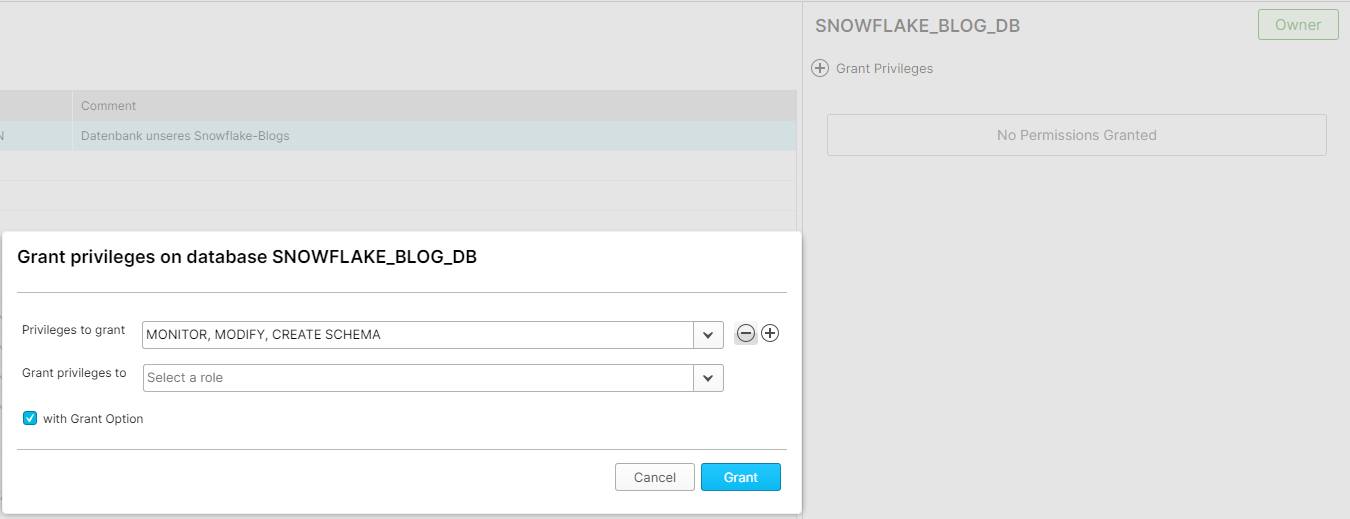
Ist unsere Datenbank in der Tabelle ausgewählt können wir im rechten Teil unseres Bildschirms Berechtigungen verwalten. Auf +Grant Privileges können wir bestimmte Privilegien (bspw. Modify, Create Schema, Monitor etc.) unseren Rollen zuweisen. Da wir allerdings mit der Rolle SYSADMIN arbeiten, brauchen wir keinerlei Berechtigungen zuweisen bzw. neue Rollen erstellen. Wir haben die vollen Berechtigungen auf unserem System.
Nun können wir unter dem Reiter Worksheets oben rechts unsere Rolle, Warehouse, Datenbank und Schema auswählen. Die Rolle belassen wir auf SYSADMIN, als Warehouse wählen wir unser erstelltes SNOWFLAKE_BLOG aus, als Datenbank nutzen wir unsere just erzeugte SNOWFLAKE_BLOG_DB und als Schema nutzen wir PUBLIC. Da wir bei unserem Warehouse die Option Auto Resume gewählt haben, brauchen wir unser Wareshouse nicht per Hand starten. Wir können unsere Datenbanken beliebig mit unseren Warehhouses verknüpfen. Das heißt, dass jede Datenbankinstanz mit jedem unserer Cluster ad hoc geändert werden kann, um z.B. auf sich ändernde Datenvolumina oder -last reagieren zu können.

Ähnlich wie andere gängige Datenbankplattformen bietet auch Snowflake die DUMMY-Tabelle DUAL. Hierbei handelt es sich um eine einzeilige Default-Tabelle, die ohne eine vorherige Erzeugung von Tabellen abgefragt werden kann. Beispielsweise Berechnungen oder Funktionen, um das Systemdatum auszugeben, können ausgeführt werden. Also ideal für uns, um uns etwas vertrauter mit dem Worksheet Tab zu machen.
Wir können direkt mit einer ersten Testabfrage beginnen:
SELECT SYSDATE() AS ZEITSTEMPEL FROM DUAL;
Die SYSDATE()-Funktion gibt uns das aktuelle Datum inklusive Uhrzeit als Zeitstempel zurück. Das Ergebnis sollte wie folgt aussehen:
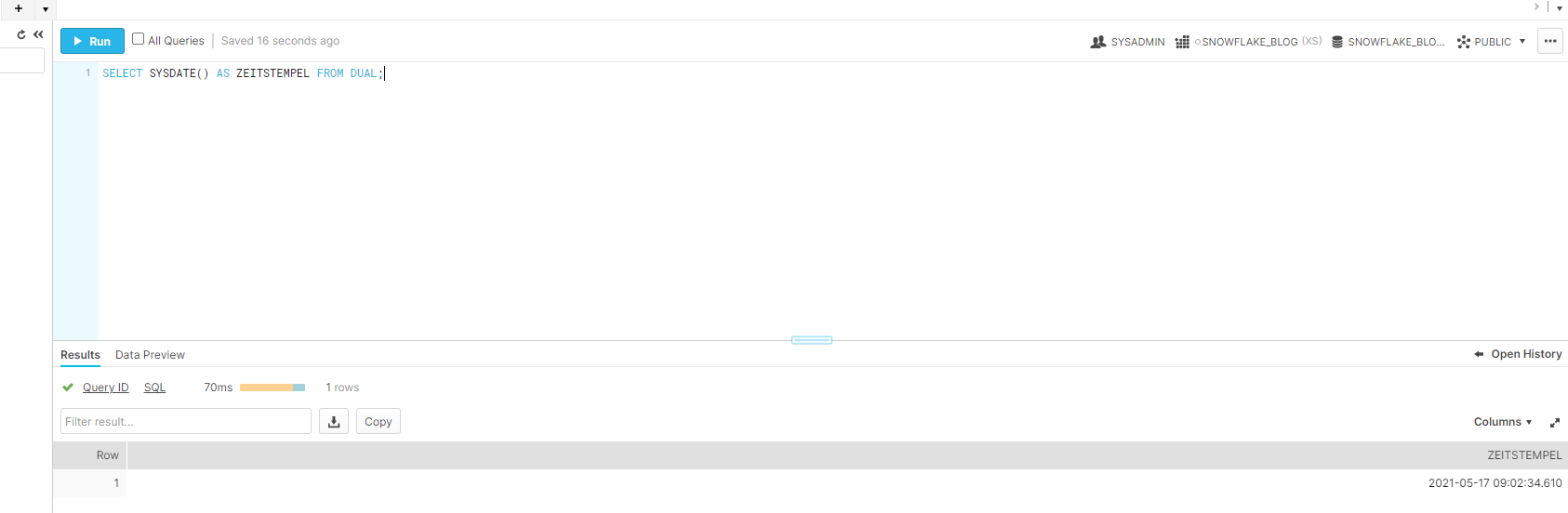
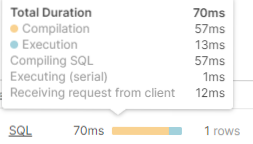
Mit einem Mouseover über den gelben/blauen Balken, welcher uns die Rechenzeit des ausgeführten SQLs anzeigt, können wir uns die Gesamtlaufzeit anschauen, die unsere Abfrage sowohl für die Kompilierung als auch die Ausführung benötigt hat. In diesem Beispiel war so gut wie kaum Rechenleistung notwendig.
Nun könnt Ihr etwas experimentieren und Euch mit der Oberfäche weiter vertraut machen. Erstellt ruhig ein paar weitere Abfragen oder Berechnungen auf Basis der DUAL-Tabelle.
Wenn ihr ein paar weitere SQLs ausgeführt habt, können wir im rechten Teil des Bildschirms die Historie begutachten. Mit einem Klick auf ß Open History sehen wir unsere bisher ausgeführten Abfragen.
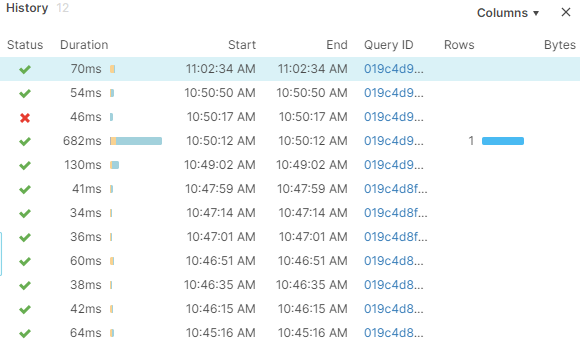
Über die Query ID, ein eindeutiger Schlüssel um jedes ausgeführte SQL auf einer Datenbank zu identifizieren und nachzuverfolgen, können wir uns Informationen über diese Abfragen ansehen. Wir klicken auf eine der Abfragen und können Informationen wie u. a. Datum und Uhrzeit der Abfrage, Ausführung durch welchen User, das SQL und das Abfrageergebnis einsehen.
Nachdem wir nun ein Warehouse und eine Datenbank erstellt haben und uns mit dem Worksheet etwas vertrauter gemacht haben, werden wir uns im nächsten Beitrag u. a. ein eigenes Set von Daten hochladen, die dazugehörigen Tabellen erzeugen und mit diesen Beispieldaten etwas arbeiten.
Snowflake bietet darüber hinaus eine eigene Datenbank mit Beispieldaten: SNOWFLAKE_SAMPLE_DATA
Wer also ganz ungeduldig bzw. neugierig ist und bereits mit Beispieldaten experimentieren und probieren möchte, kann sich innerhalb dieser Beispieldatenbank im Rahmen der Free-Trial-Version „austoben“.
Bis zum nächsten Blogeintrag unserer Getting Started Serie!
Hier findest du unsere weiteren Cloud-BI Blogbeiträge
(1) - Keine Schneeballschlacht mit Daten
(2) - Snowflake – Getting Started #1 Erstellung eines kostenlosen Testaccounts und Erklärung der UI
(3) - Matillion ETL – Datenintegration für und in der Cloud
(4) - Snowflake – Getting Started #2 Erstellung eines Virtual Warehouses und einer Datenbank
(5) - Matillion ETL - Hands On