
Snowflake – Getting Started #1 Erstellung eines kostenlosen Testaccounts und Erklärung der UI
Im Rahmen dieser Blogserie werden wir Euch Schritt-für-Schritt mit in die Wolke nehmen, damit Ihr Eure ersten eigenen Gehversuche und Erfahrungen mit Snowflake sammeln könnt.
Snowflake bietet einen kostenlosen 30-Tage Testzugang an. Dieser beinhaltet einen Credit-Wert von $400 zur freien Nutzung. Dadurch, dass nach Nutzung (Abfragen, Inserts, etc.) abgerechnet wird, können wir über diese Credits innerhalb unserer Testnutzung frei verfügen. Da wir in unserer Serie in der Regel mit kleinen Datenmengen arbeiten, ist dies mehr als ausreichend für unsere Zwecke.
Genug geredet, legen wir mit der Erstellung unseres Testaccounts los!
Auf https://trial.snowflake.com/ können wir uns den angesprochenen Trial-Account erstellen. Nachdem wir unsere persönlichen Informationen eingetragen haben, kommt die Auswahl der Edition und des Cloud Anbieters (Abbildung 1). Wir wählen die Enterprise Edition, um uns die Arbeit mit erweiterten Funktionen der Snowflake zu ermöglichen. Als Region wählen wir die uns nächstgelegene aus. In unserem Beispiel haben wir uns für den Cloud Provider AWS entschieden. Ihr könnt natürlich auch eine andere Auswahl treffen. Diese wird jedoch von unserer Blogversion entsprechend abweichen.

Mit Abschluss der Anmeldung erhalten wir eine E-Mail für unsere Accountaktivierung. Nachdem unser Account erfolgreich aktiviert wurde, erhalten wir eine weitere Mail mit einer URL zu unserer just erzeugten Snowflake-Instanz, welche in einer AWS Cloud betrieben wird.
Nun können wir den zugesandten Link mit einem Browser unserer Wahl öffnen und uns anmelden. Nach erfolgreicher Anmeldung können wir die offenen „Welcome“- und „Help“-Popups schließen. Eure neue Snowflake-Instanz sollte nun wie folgt aussehen:
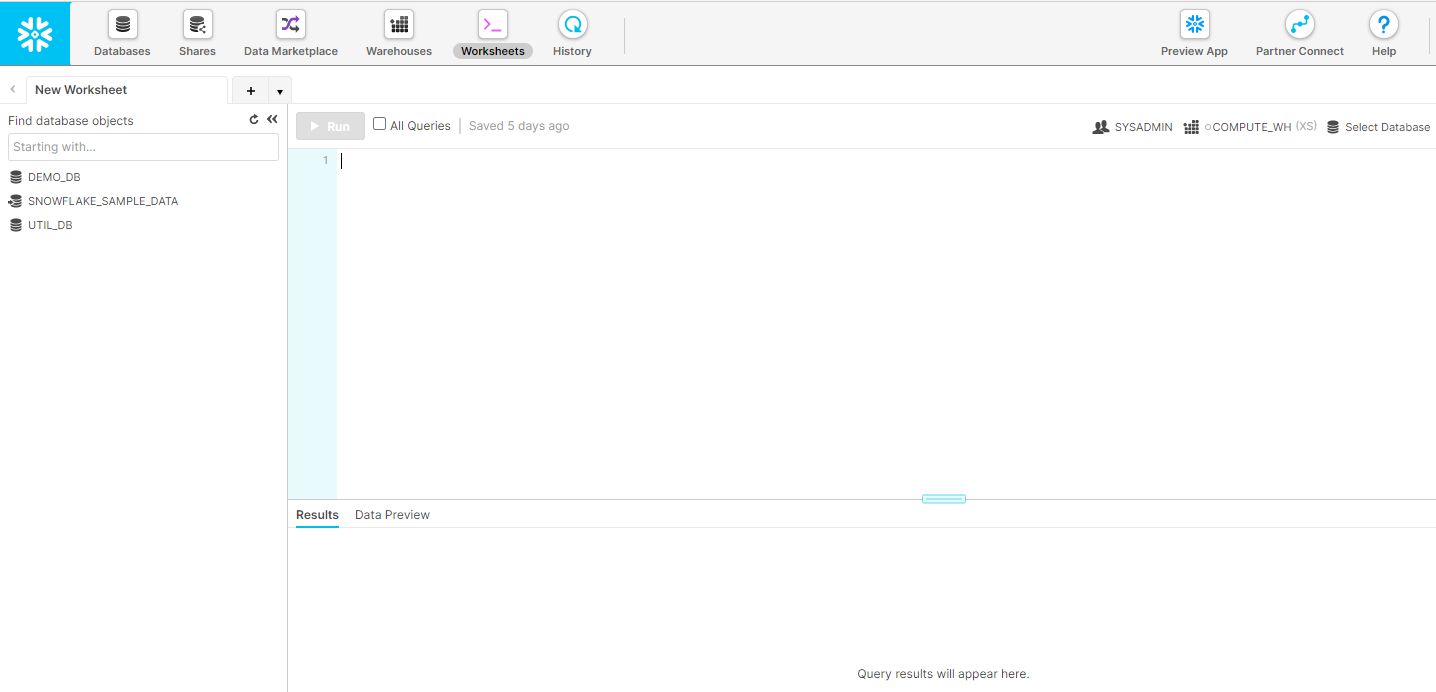
Bevor es ans „Eingemachte“ geht, schauen wir uns das User Interface mal etwas genauer an und machen uns mit der Benutzeroberfläche vertraut. Snowflake wird als Cloud Native Datenbank direkt über den Browser verwaltet und administriert. Auch sämtliche Arbeiten auf der Datenbank, wie z.B. Abfragen, Anlage und Anpassung von Tabellen oder Updates/Inserts, können direkt über den Browser erzeugt und ausgeführt werden. Einige SQL-Entwicklerwerkzeuge unterstützen bereits eine Konnektivität zu Snowflake. Somit könnt Ihr gegebenenfalls mit Eurem vertrauten Tool weiterarbeiten.
Fangen wir oben links mit dem Menü an, wo wir uns durch die verschiedenen Bereiche der Snowflake navigieren können.
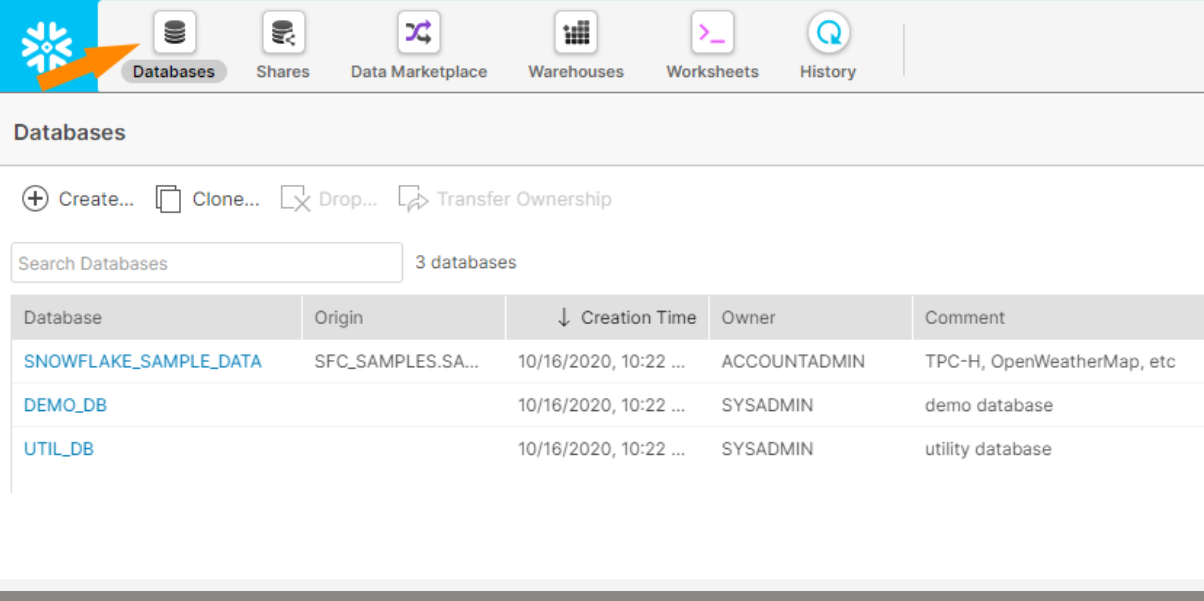
Mit einem Klick auf den Reiter „Databases“ bekommen wir einen Überblick über sämtliche Datenbankinstanzen, auf die wir zugreifen können. Darüber hinaus können wir hier neue Datenbanken erstellen, klonen, löschen oder den Owner der Datenbank (in der Regel derjenige, der die Datenbank erzeugt hat) auf einen anderen Nutzer übertragen.
Wir sehen bereits drei erstellte Datenbankinstanzen. Diese Beispieldatenbanken beinhalten einfache Daten zum Experimentieren. Prädestiniert, um direkt loszulegen, oder?
Eigentlich ja… jedoch wollen wir uns noch etwas vertrauter mit der Benutzeroberfläche machen. Wir müssen uns noch ein klein wenig gedulden.
Den Reiter „Shares“ können wir überspringen. Hier können Snowflake-Objekte wie, bspw. Tabellen, zwischen Snowflake-Accounts und auch externen Benutzern geteilt werden. Dieser Bereich ist für uns derzeit nicht relevant.
Das Gleiche gilt für den Reiter „Data Marketplace“. Dieser Marktplatz bietet die Möglichkeit Datasets vieler unterschiedlicher Themenbereiche für sich zu nutzen. Somit kann auf Daten von Drittanbietern zugegriffen werden und diese direkt in unserer eigenen Snowflake-Instanz abgefragt werden. Hierdurch kann der unternehmensweite Datenschatz mit Daten aus dem Marketplace verknüpft werden.
Unter „Warehouses“ können wir unsere erstellten „Virtual Warehouses” verwalten. „Virtual Warehouses“ (in der Regel nur Warehouses genannt) sind unsere Cluster-Instanzen, in denen sämtliche Berechnungen einer Datenbank stattfinden. Dadurch werden entsprechende Ressourcen wie CPU und (Arbeits-)Speicher einem Warehouse zugewiesen. Operationen, bspw. Abfragen, werden innerhalb eines Warehouses ausgeführt. Die verbrauchten Ressourcen eines Warehouses stehen in direkter Relation zu den genutzten bzw. verbrauchten Snowflake-Credits.
Wir sehen ein bereits vorab erstelltes Warehouse COMPUTE_WH und können uns mit der Übersicht etwas vertrauter machen. Wir können sämtliche Metainformationen zu unseren Warehouses sehen, wie bspw. die eingestellte Größe (hierzu im nächsten Blogeintrag mehr), die Anzahl der Cluster, die derzeitige Last u.v.m.
Auch können wir hier, ähnlich zu den Datenbanken, neue Warehouses erstellen, löschen oder bestehende editieren.

Durch einen Klick auf den Namen des bereits erstellten Warehouses COMPUTE_WH können wir Statistiken der Last und Laufzeiten sehen. Da wir allerdings noch keine Last auf diesem Warehouse erzeugt haben, ist hier noch nichts zu sehen.
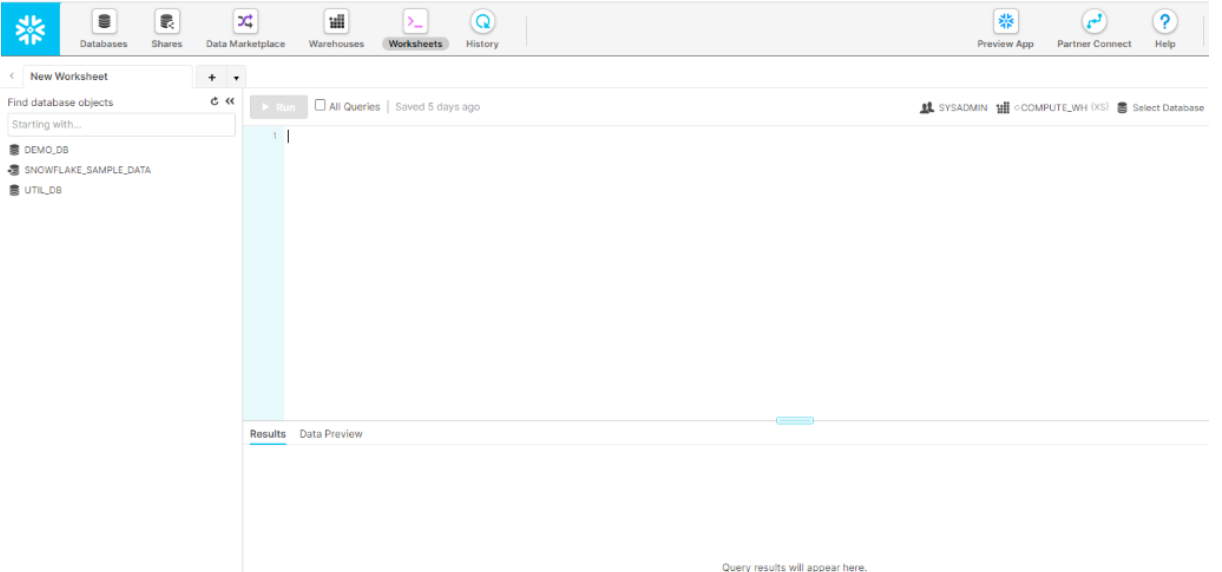
Das „Worksheet“ ist unser browserbasierter SQL-Editor. Hier können wir unsere SQL-Querys, DDLs oder DMLs gegen unsere Datenbank absetzen und die Ergebnisse anzeigen. Links im Bild sehen wir unsere bisherigen Datenbanken, die wir bereits aus dem Datenbank-Tab kennen. Rechts sehen wir unsere derzeitige Rolle, mit der wir unsere Befehle ausführen, sowie das Warehouse, auf der die Berechnung ausgeführt werden soll.
Unter „History“ können wir sämtliche Operationen in unseren Warehouses einsehen und detaillierte Informationen über jede einzelne Abfrage erhalten. Dies beinhaltet Informationen zur Laufzeit, den abgesetzten Befehl als solchen und viele weitere Metainformationen. Dadurch, dass wir noch nicht viele Berechnungen auf der Datenbank erzeugt haben, ist hier noch nicht allzu viel zu sehen.
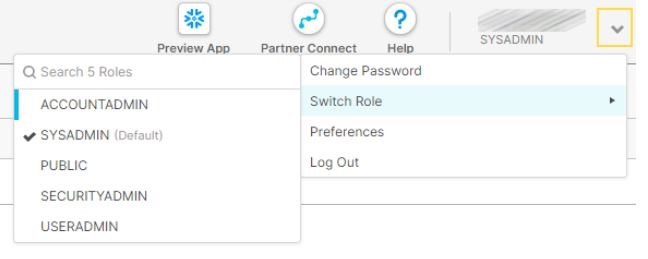
Mit einem Klick auf den Pfeil oben rechts, neben unserem Benutzernamen, haben wir die Möglichkeit unsere (Account-)Einstellungen anzupassen und können unsere Rolle auswählen. Standardmäßig ist die SYSADMIN Rolle ausgewählt. Diese können wir für unsere ersten Schritte in Snowflake auch ausgewählt lassen. Dadurch haben wir für unser weiteres Vorhaben keinerlei Einschränkungen, was die Berechtigungen angeht.
Jetzt, wo wir einen groben Überblick über das User Interface und die einzelnen Funktionen haben, können wir beginnen unser erstes Warehouse und eine Datenbank anzulegen. Darüber hinaus werden wir unsere ersten Tabellen und Daten laden ...
… allerdings erst im vierten Teil dieser Blogserie!
Hier findest du unsere weiteren Cloud-BI Blogbeiträge
(1) - Keine Schneeballschlacht mit Daten
(2) - Snowflake – Getting Started #1 Erstellung eines kostenlosen Testaccounts und Erklärung der UI
(3) - Matillion ETL – Datenintegration für und in der Cloud
(4) - Snowflake – Getting Started #2 Erstellung eines Virtual Warehouses und einer Datenbank
(5) - Matillion ETL - Hands On